

Pythonでデータ可視化をする際、seabornは強力で使いやすいライブラリです。このチュートリアルでは、seabornの基本的な使い方から実践的なテクニックまで、実例を交えながら段階的に解説します。データからインサイトを引き出す力を身につけましょう。
- seabornの主な特徴と利点
- seabornのインストール方法
- データの読み込みと前処理の方法
- 基本的なプロット作成の流れ
- 散布図、ヒストグラム、棒グラフなどの作成方法
- カテゴリ変数の比較や変数間の関係性の可視化テクニック
- ファセットグリッドを使った多変数データの可視化
- カスタムスタイルの適用とデザイン調整
- seabornを使いこなすコツとデータビジュアライゼーションのベストプラクティス
seabornとは?Pythonデータ可視化ライブラリの特徴と利点
Pythonでデータ可視化をする際、matplotlibは広く利用されているライブラリですが、統計データの可視化に特化した高レベルのライブラリとして、seabornが注目を集めています。seabornは、洗練された美しいグラフを簡単に作成できることが大きな特徴です。
seabornの概要と強み
seabornは、matplotlibをベースに開発されたPythonのデータ可視化ライブラリです。matplotlibの機能を拡張・簡素化し、統計データの可視化に特化することで、複雑なデータの中から意味のあるパターンや傾向を見つけ出すのに優れたツールとなっています。
seabornの大きな強みは、デフォルトの設定がデータに合わせて最適化されている点です。そのため、ユーザーは細かい調整をしなくても、プロフェッショナルな仕上がりのグラフを作成できます。また、豊富なカラーパレットやスタイルが用意されているので、目的に合ったデザインを選択することができます。
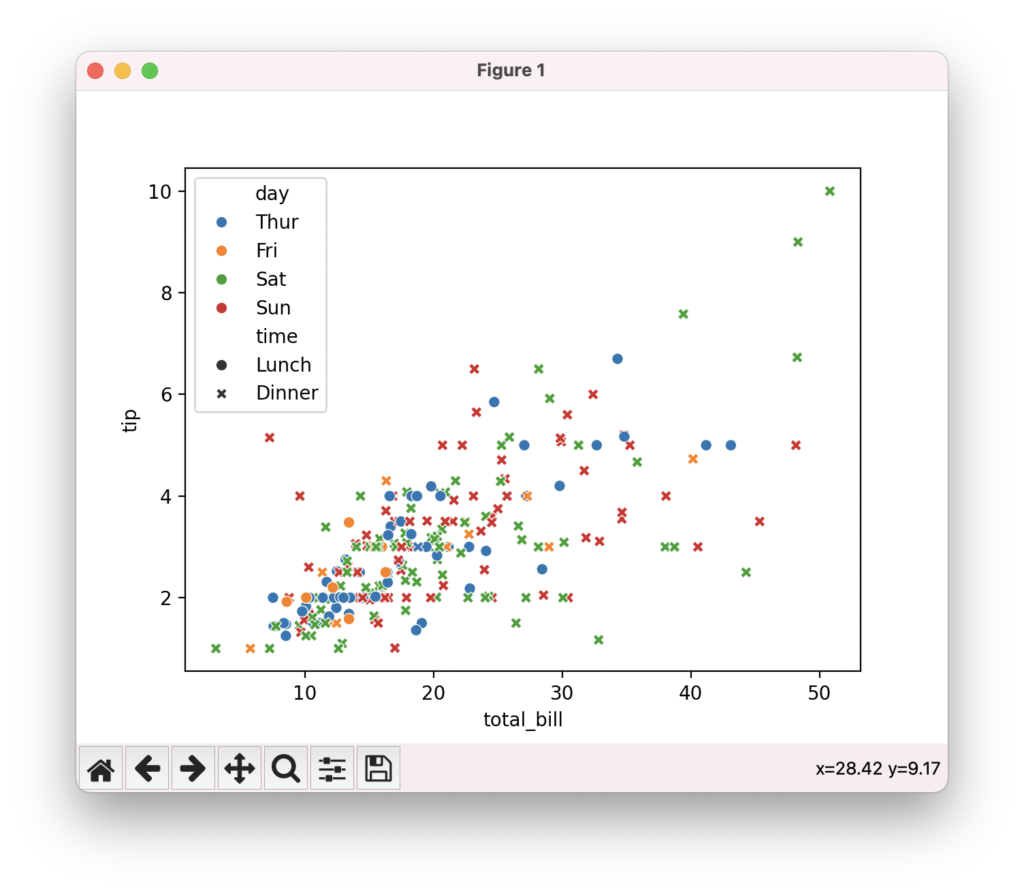
例えば、以下のコードは、わずか数行でデータの傾向を捉えた美しい散布図を作成しています。
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
tips = sns.load_dataset("tips")
# 散布図の作成
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="day", style="time")
plt.show()
seabornとmatplotlibの違い
seabornとmatplotlibは、どちらもPythonのデータ可視化ライブラリですが、いくつかの重要な違いがあります。
matplotlibは汎用的で柔軟性の高い低レベルのライブラリです。グラフの細部まで自由にカスタマイズできる反面、コードが長くなりがちという特徴があります。一方、seabornはmatplotlibをラップした高レベルのライブラリで、統計データの可視化に特化し、シンプルで直感的なAPIを提供しています。
また、matplotlibは幅広いグラフの種類に対応しているのに対し、seabornは統計グラフに絞って機能を提供しているという違いもあります。seabornは美しいデフォルトテーマを備えているため、最小限のコードできれいなグラフを作成できます。
ただし、seabornはmatplotlibをベースにしているため、両者を組み合わせて使うこともできます。seabornで作成したグラフをmatplotlibで微調整するといった使い方も可能です。
seabornは、統計データの可視化に優れたシンプルで強力なツールです。美しいグラフを手軽に作成できる利点から、データサイエンティストやデータアナリスト、研究者に広く愛用されています。次章では、seabornのインストール方法と基本的な使い方について解説します。
seabornのインストールと基本的な使い方
seabornを使ったデータ可視化を始めるには、まずseabornをインストールし、データの読み込みと前処理を行う必要があります。ここでは、seabornのインストール方法から、基本的なプロット作成の流れまでを解説します。
seabornのインストール方法
seabornはPyPIに登録されているパッケージなので、pipを使って簡単にインストールできます。以下のコマンドを実行するだけで、seabornがインストールされます。
pip install seaborn
仮想環境を使っている場合は、事前に仮想環境を作成・アクティベートしてからインストールを行うのが望ましいでしょう。
python -m venv myenv source myenv/bin/activate pip install seaborn
Anacondaを使っている場合は、conda経由でもseabornをインストールできます。
インストールが完了したら、Pythonインタープリタやノートブック上でseabornをimportして、正しくインストールされたことを確認しましょう。
import seaborn as sns print(sns.__version__)
データの読み込みと前処理
seabornでデータを可視化するには、pandasのDataFrameを使うのが一般的です。CSVやTSVファイル、またはデータベースから読み込んだデータをDataFrameに変換し、欠損値の処理、データ型の変換、特徴量の選択など、目的に応じたデータの前処理を行います。
seabornには、有名なデータセットがいくつか組み込まれています。これらを使えば、サンプルデータですぐに可視化を試すことができます。
import seaborn as sns
import pandas as pd
# サンプルデータセットの読み込み
tips = sns.load_dataset("tips")
# DataFrameの概要を確認
print(tips.head())
print(tips.info())
# 必要な列の選択
tips = tips[['total_bill', 'tip', 'size', 'time', 'day']]
# 欠損値の確認と削除
print(tips.isnull().sum())
tips = tips.dropna()
基本的なプロット作成の流れ
データの準備ができたら、いよいよseabornを使ってプロットを作成します。seabornのプロット関数は、データとビジュアライゼーションの種類を指定するだけで、美しいグラフを作成できるのが特徴です。
seabornには、figure-levelとaxes-levelの2種類のインターフェースがあります。figure-levelは簡潔に記述できますが融通が利きません。一方、axes-levelは冗長ですが、グラフの細かな調整が可能です。
import seaborn as sns
import matplotlib.pyplot as plt
# figure-levelインターフェース
sns.relplot(data=tips, x="total_bill", y="tip", hue="day", kind="scatter")
plt.show()
# axes-levelインターフェース
fig, ax = plt.subplots(figsize=(8, 6))
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="day", ax=ax)
ax.set_title("Scatter plot of total bill vs. tip")
plt.show()
プロット関数の引数で、使用する変数やグラフの見た目をカスタマイズできます。作成したグラフを表示するには、matplotlibのplt.show()を呼び出します。
seabornのインストールとデータの準備、基本的なプロット作成の流れを押さえたところで、次は実際のデータ可視化テクニックを見ていきましょう。次章では、seabornを使った様々なグラフの作り方を、サンプルコードとともに解説します。
10の実例で学ぶ!seabornを使ったデータ可視化テクニック
seabornは、統計データの可視化に特化した多彩なプロット機能を提供しています。一変数や二変数の分布、カテゴリ変数の比較、変数間の関係性の可視化など、様々な場面で活用できます。プロットの種類によって、使い分けのポイントや表現できる情報が異なるため、実際のデータセットを使った具体的なコード例を通して、各プロットの特徴と使い方を理解していきましょう。データの傾向や課題が一目で把握できるような、わかりやすいビジュアライゼーションを目指します。
散布図の作成と回帰直線の表示
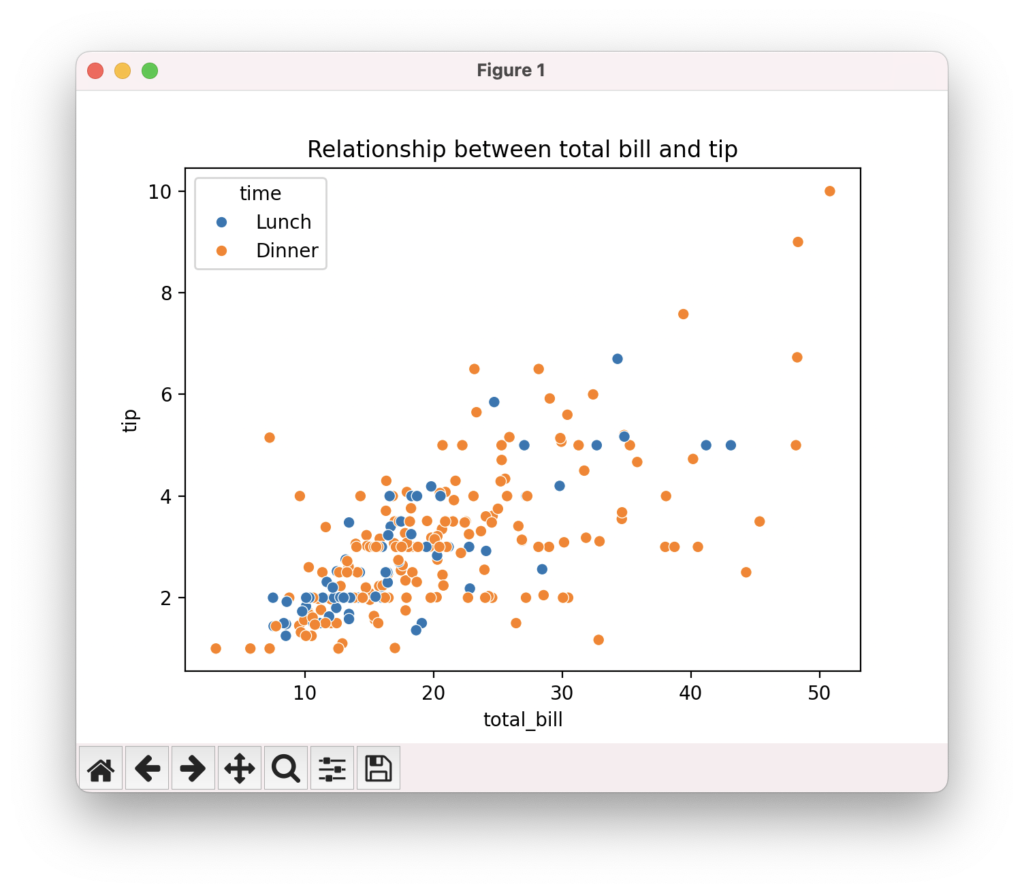
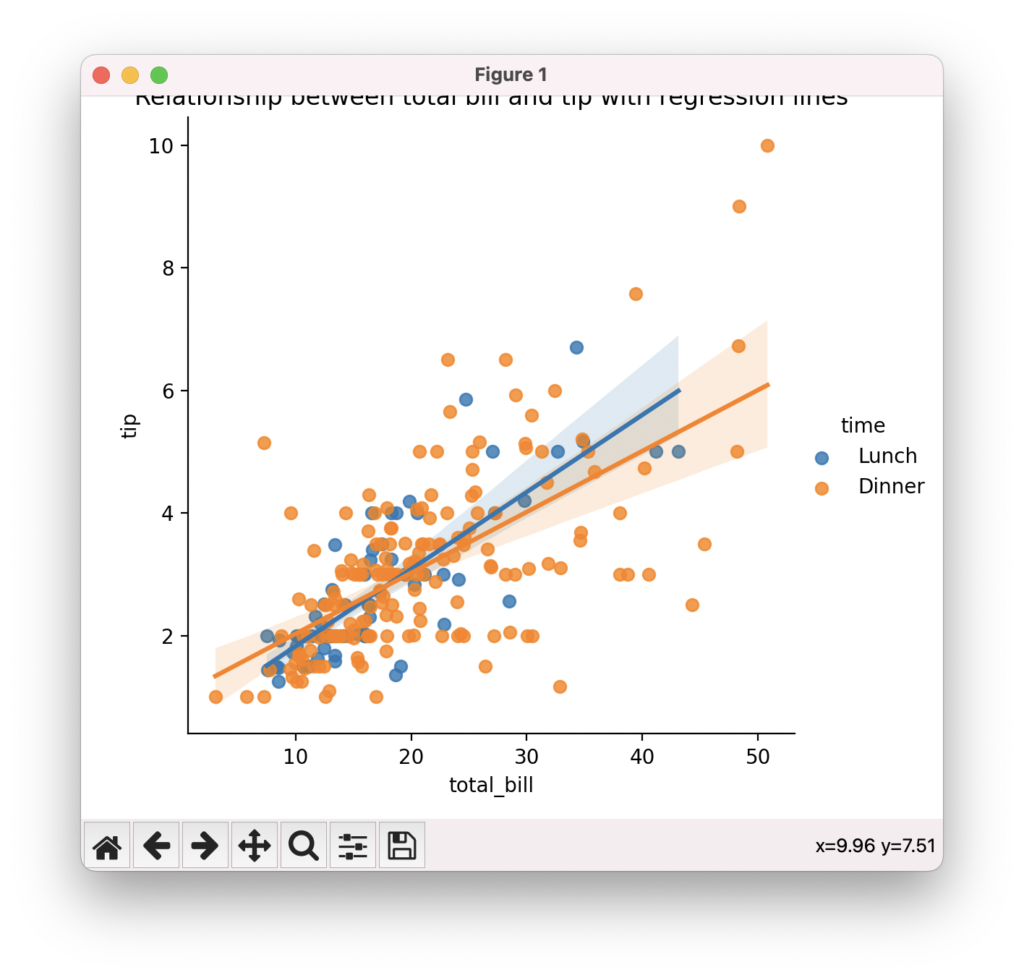
散布図は、2つの連続変数の関係性を可視化するのに適したプロットです。seabornのscatterplot()関数を使って、簡単に散布図を作成できます。hueパラメータを指定することで、サードパーティのカテゴリ変数に基づいて色分けできます。lmパラメータをTrueにすると、線形回帰直線を重ねて表示できます。相関関係の強さや外れ値の存在など、変数間の関係性を視覚的に把握できます。
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
tips = sns.load_dataset("tips")
# 散布図の作成
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")
plt.title("Relationship between total bill and tip")
plt.show()
# 回帰直線の表示
sns.lmplot(data=tips, x="total_bill", y="tip", hue="time")
plt.title("Relationship between total bill and tip with regression lines")
plt.show()
ヒストグラムとカーネル密度推定
ヒストグラムは、データの分布を視覚化するための基本的なプロットです。seabornのhistplot()関数を使って、ビン幅を自動調整したヒストグラムを作成できます。kdeパラメータをTrueにすると、カーネル密度推定曲線を重ねて表示できます。複数のヒストグラムを重ねて表示することで、グループ間の分布の違いを比較できます。分布の形状、歪度、複数のピークの存在など、データの特性を視覚的に捉えられます。
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
tips = sns.load_dataset("tips")
# ヒストグラムの作成
sns.histplot(data=tips, x="total_bill", kde=True)
plt.title("Distribution of total bill")
plt.show()
# 複数のヒストグラムの比較
sns.histplot(data=tips, x="total_bill", hue="time", kde=True, multiple="stack")
plt.title("Distribution of total bill by time")
plt.show()
棒グラフとエラーバーの表示
棒グラフは、カテゴリ変数の値ごとの集計結果を比較するのに適したプロットです。seabornのbarplot()関数を使って、カテゴリ別の平均値や合計値を棒グラフで表示できます。ciパラメータを指定することで、信頼区間や標準偏差をエラーバーとして表示できます。hueパラメータを指定すると、サードパーティのカテゴリ変数に基づいて色分けできます。カテゴリ間の大小関係や順位、エラーバーの大きさから統計的有意性を視覚的に評価できます。
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
tips = sns.load_dataset("tips")
# 棒グラフの作成
sns.barplot(data=tips, x="day", y="total_bill", ci="sd")
plt.title("Average total bill by day")
plt.show()
# hueパラメータの指定
sns.barplot(data=tips, x="day", y="total_bill", hue="sex", ci="sd")
plt.title("Average total bill by day and sex")
plt.show()
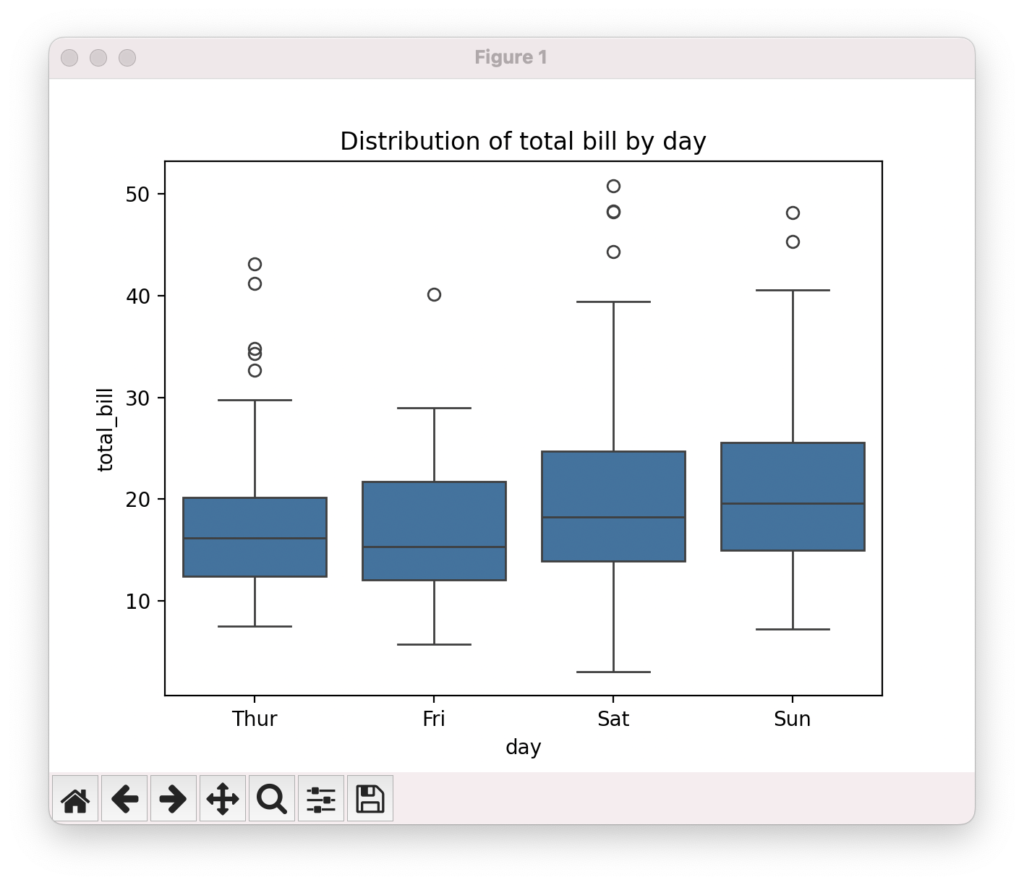
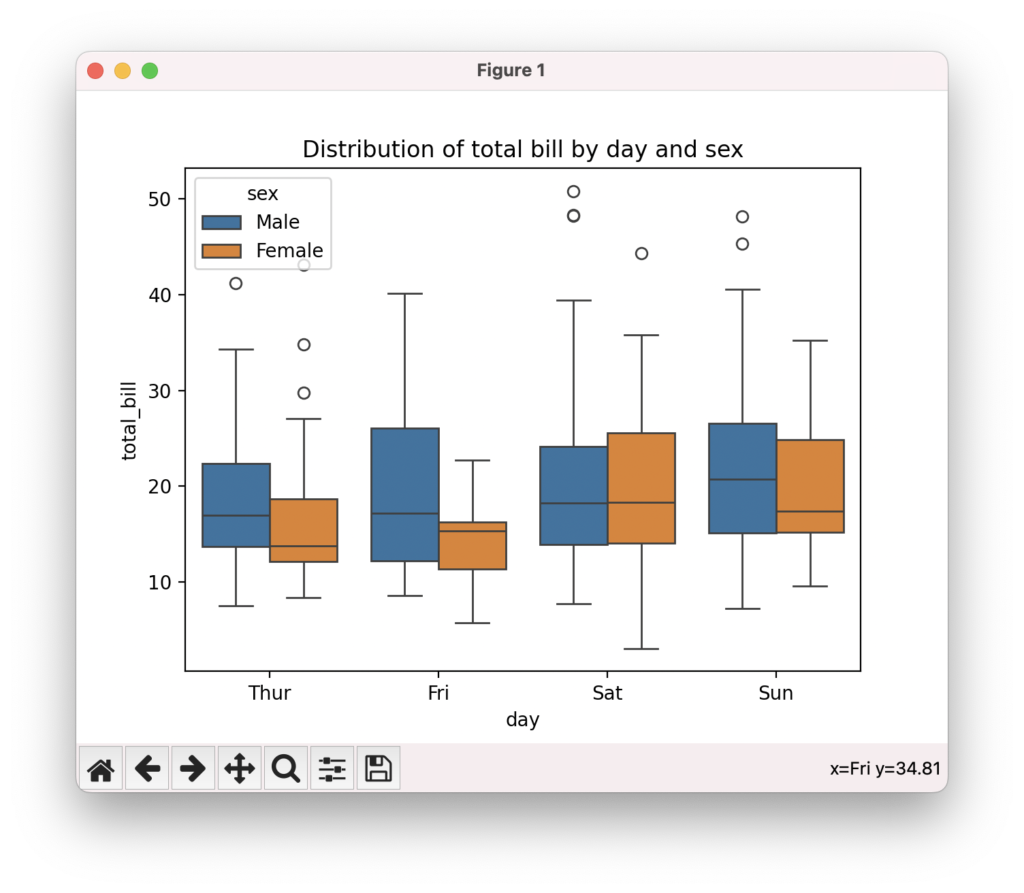
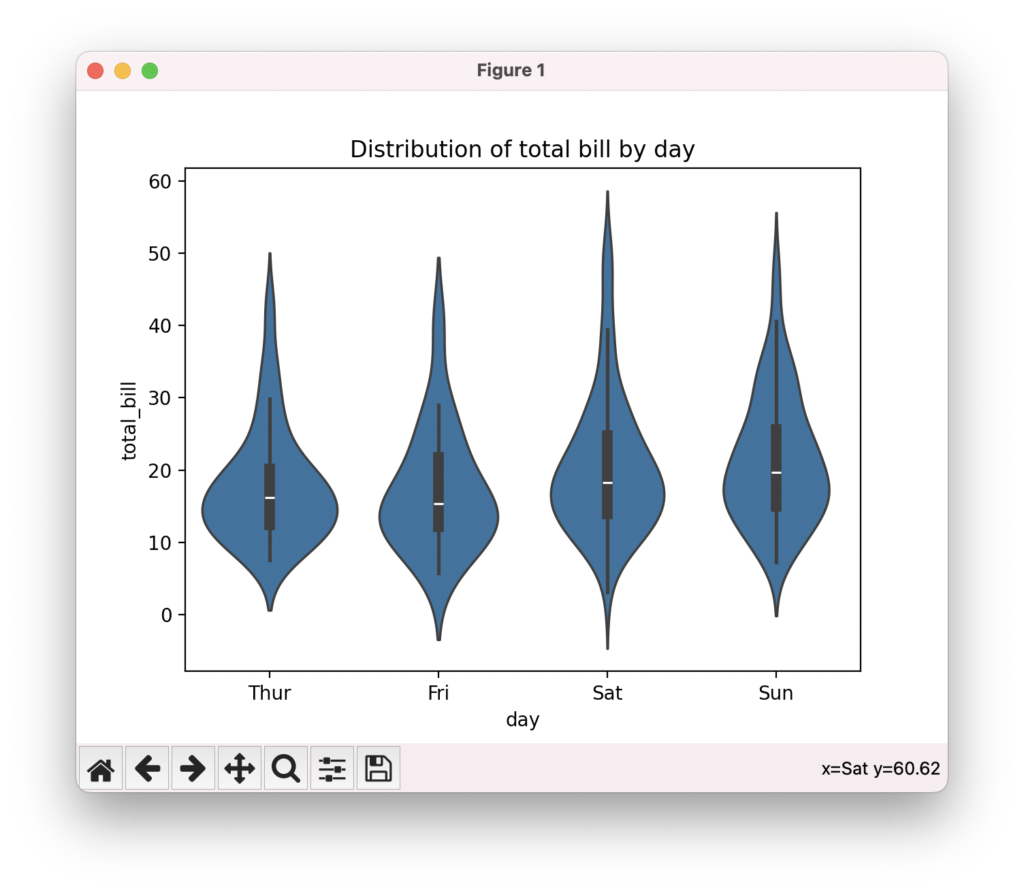
箱ひげ図で分布を比較
箱ひげ図は、複数のグループの分布を比較するのに適したプロットです。seabornのboxplot()関数を使って、グループごとの四分位点、中央値、外れ値を表示できます。hueパラメータを指定すると、サードパーティのカテゴリ変数に基づいて色分けできます。グループ間の中央値の差異、分散の大きさ、外れ値の存在など、分布の特徴を視覚的に比較できます。
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
tips = sns.load_dataset("tips")
# 箱ひげ図の作成
sns.boxplot(data=tips, x="day", y="total_bill")
plt.title("Distribution of total bill by day")
plt.show()
# hueパラメータの指定
sns.boxplot(data=tips, x="day", y="total_bill", hue="sex")
plt.title("Distribution of total bill by day and sex")
plt.show()
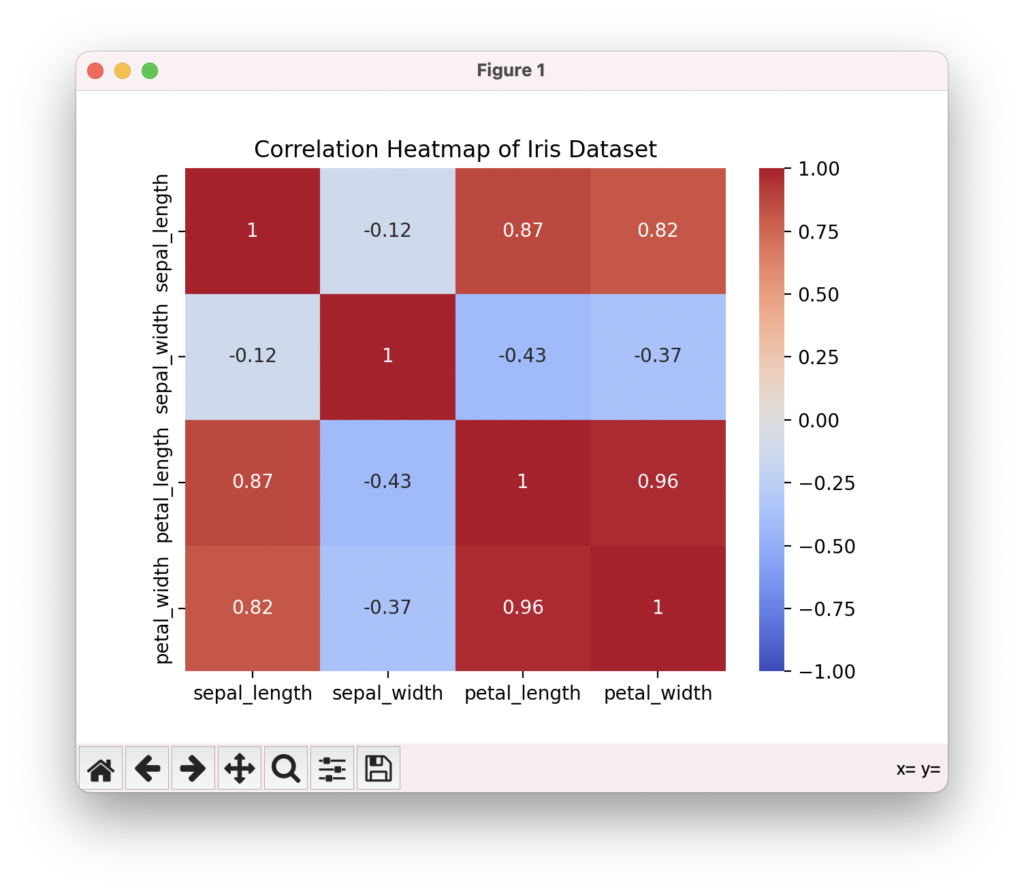
ヒートマップで変数間の相関を可視化
ヒートマップは、複数の変数間の相関係数を色の濃淡で表現するプロットです。seabornのheatmap()関数を使って、相関行列をヒートマップで可視化できます。annot=Trueを指定すると、セル内に相関係数の値を表示できます。cmap引数でカラーマップを指定することで、色の見え方を調整できます。変数間の正負の相関関係、強い相関を持つ変数のペアなどを視覚的に把握できます。
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
iris = sns.load_dataset("iris")
# Select only the numeric columns
numeric_columns = iris.select_dtypes(include=['float64', 'int64']).columns
iris_numeric = iris[numeric_columns]
# Calculate the correlation matrix
corr = iris_numeric.corr()
# Create the heatmap
sns.heatmap(corr, annot=True, cmap="coolwarm", vmin=-1, vmax=1)
plt.title("Correlation Heatmap of Iris Dataset")
plt.show()
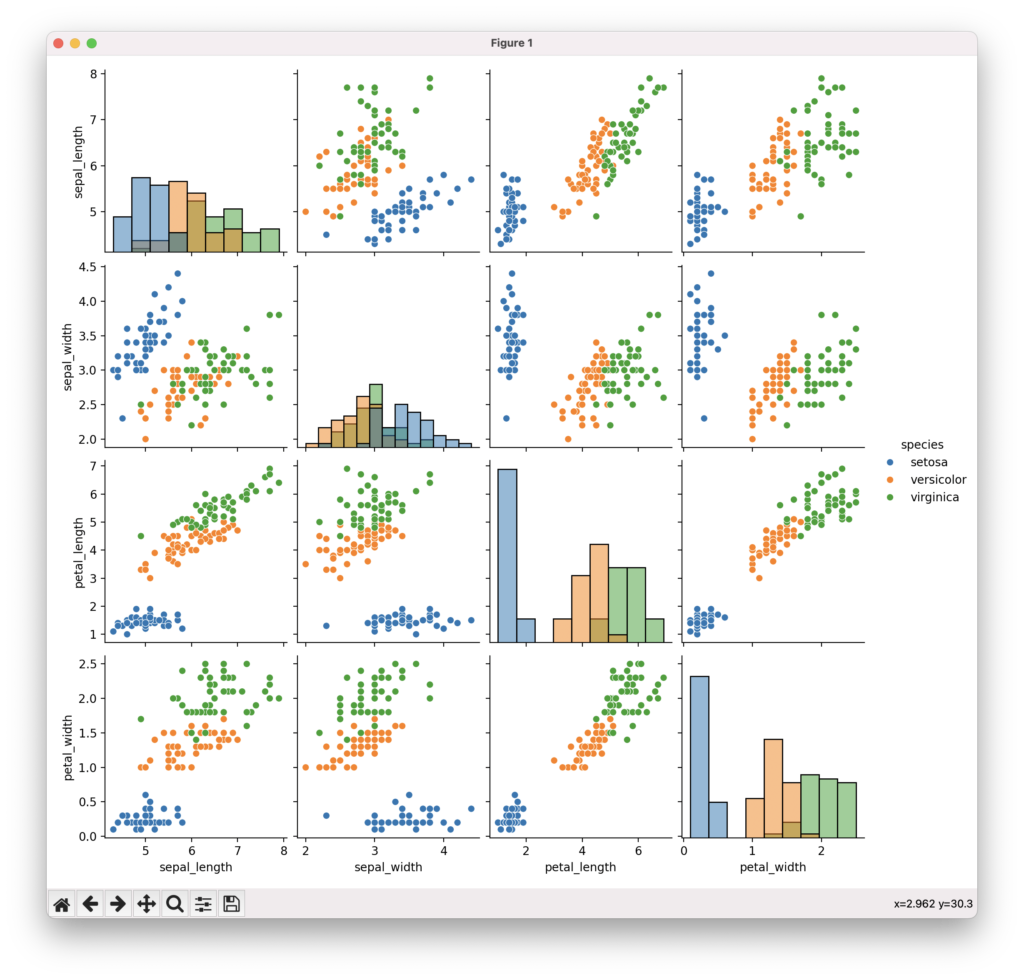
ペアプロットで変数間の関係を探索
ペアプロットは、データセット内の複数の変数を組み合わせて散布図行列を作成するプロットです。seabornのpairplot()関数を使って、対角線上にヒストグラム、非対角要素に散布図を配置したペアプロットを作成できます。hue引数でカテゴリ変数を指定すると、色分けされた散布図行列を表示できます。複数の変数間の関係性を一度に俯瞰でき、興味深い関係性やパターンを発見するのに役立ちます。
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
iris = sns.load_dataset("iris")
# ペアプロットの作成
sns.pairplot(iris, hue="species", diag_kind="hist")
plt.show()
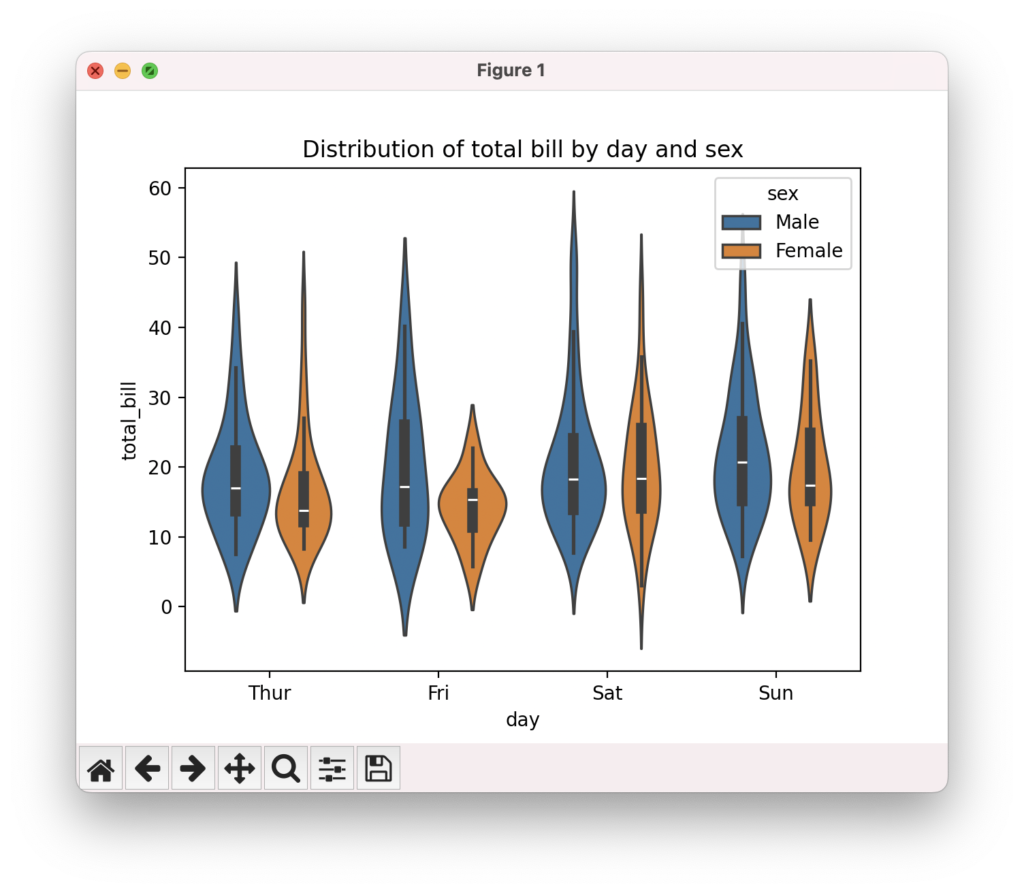
バイオリンプロットで分布形状を比較
バイオリンプロットは、カーネル密度推定を用いてグループごとのデータ分布を表現するプロットです。seabornのviolinplot()関数を使って、複数のカテゴリの分布を比較できます。内部にボックスプロットを表示することで、四分位点や中央値も同時に確認できます。hue引数でサードパーティのカテゴリ変数を指定すると、色分けされた分布を重ねて表示できます。分布の形状、複数のピークの存在、グループ間の差異などを視覚的に捉えられます。
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
tips = sns.load_dataset("tips")
# バイオリンプロットの作成
sns.violinplot(data=tips, x="day", y="total_bill", inner="box")
plt.title("Distribution of total bill by day")
plt.show()
# hueパラメータの指定
sns.violinplot(data=tips, x="day", y="total_bill", hue="sex", inner="box")
plt.title("Distribution of total bill by day and sex")
plt.show()
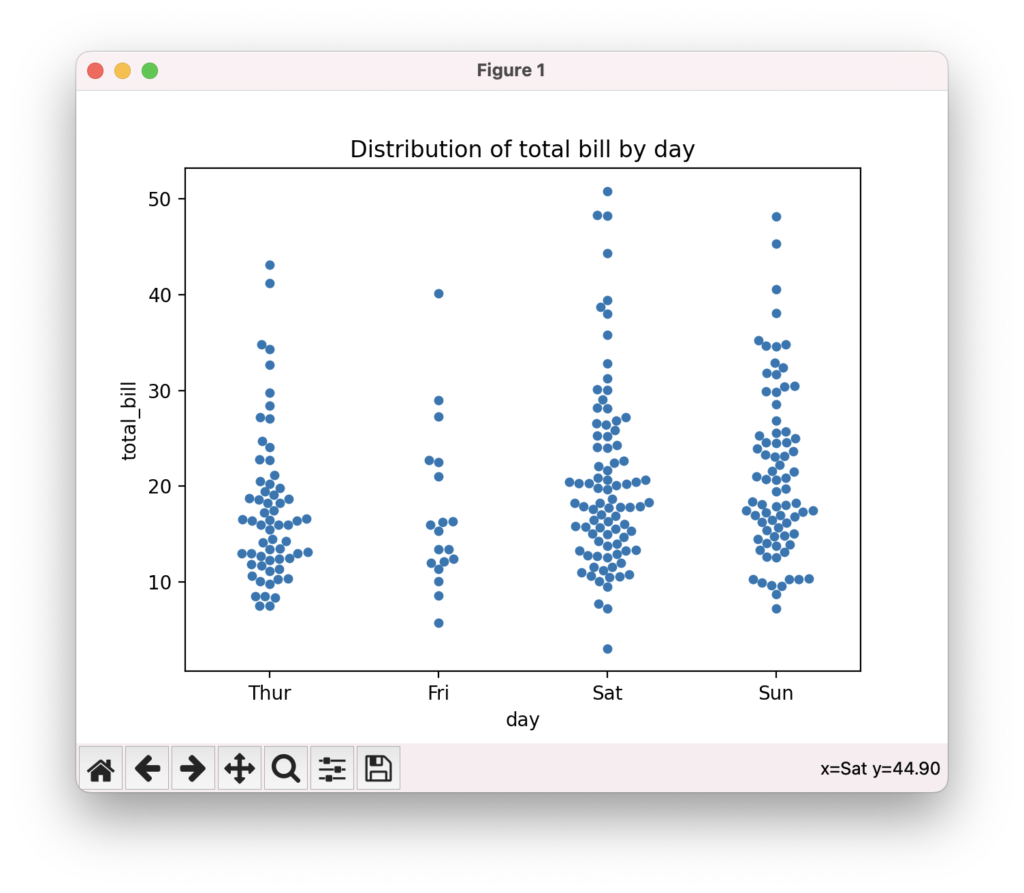
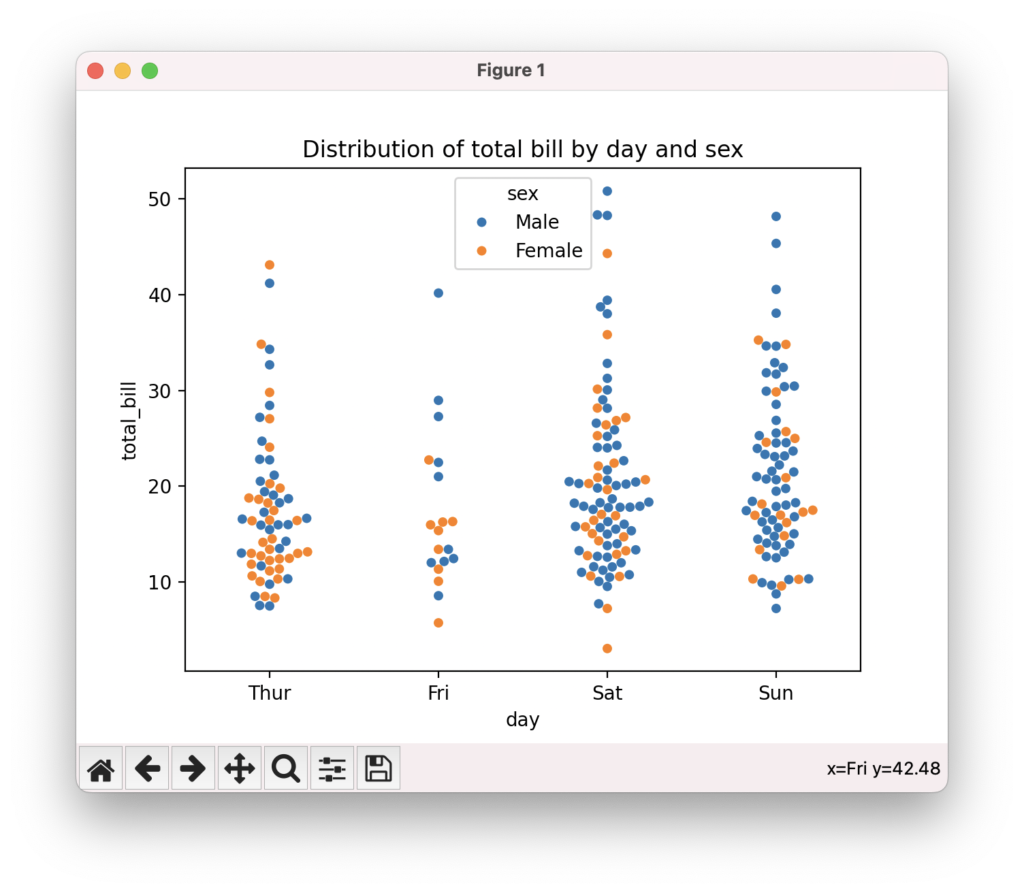
スウォームプロットでカテゴリ別のデータ分布を表示
スウォームプロットは、カテゴリ別にデータ点を重ならないように配置して分布を表現するプロットです。seabornのswarmplot()関数を使って、複数のカテゴリのデータ分布を比較できます。hue引数でサードパーティのカテゴリ変数を指定すると、色分けされたデータ点を表示できます。データ点の密度、広がり、外れ値の存在などを視覚的に把握できます。
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
tips = sns.load_dataset("tips")
# スウォームプロットの作成
sns.swarmplot(data=tips, x="day", y="total_bill")
plt.title("Distribution of total bill by day")
plt.show()
# hueパラメータの指定
sns.swarmplot(data=tips, x="day", y="total_bill", hue="sex")
plt.title("Distribution of total bill by day and sex")
plt.show()
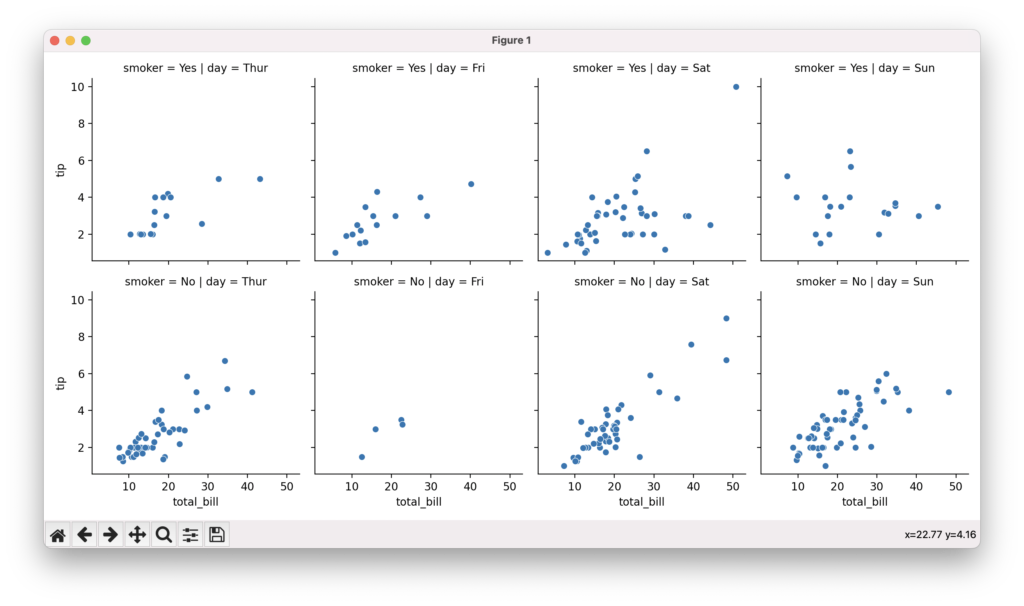
ファセットグリッドで多変数データを俯瞰
ファセットグリッドは、グリッド状に複数のサブプロットを配置して、多変数データを俯瞰するためのプロットです。seabornのFacetGrid()関数を使って、行と列に異なる変数を割り当てたグリッドを作成できます。map()メソッドでプロット関数を適用することで、各サブプロットにグラフを描画できます。カテゴリ変数の組み合わせごとにデータの傾向を比較でき、交互作用やパターンを発見するのに役立ちます。
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
tips = sns.load_dataset("tips")
# ファセットグリッドの作成
g = sns.FacetGrid(tips, col="day", row="smoker")
g.map(sns.scatterplot, "total_bill", "tip")
plt.show()
カスタムスタイルの適用とデザイン調整
seabornでは、デフォルトのスタイルを変更してグラフのデザインを調整できます。sns.set_style()関数でプロットの背景スタイルを変更したり、sns.set_palette()関数でカラーパレットを変更したりできます。また、matplotlib APIを使って、タイトル、軸ラベル、凡例などのデザイン要素を細かくカスタマイズできます。目的に応じてデザインを調整し、わかりやすく美しいビジュアライゼーションを作成しましょう。
import seaborn as sns
import matplotlib.pyplot as plt
# データセットの読み込み
tips = sns.load_dataset("tips")
# スタイルの設定
sns.set_style("whitegrid")
sns.set_palette("Set2")
# 散布図の作成
plt.figure(figsize=(8, 6))
sns.scatterplot(data=tips, x="total_bill", y="tip", size="size", sizes=(20, 200), hue="day")
plt.title("Relationship between total bill and tip", fontsize=16)
plt.xlabel("Total bill", fontsize=12)
plt.ylabel("Tip", fontsize=12)
plt.legend(title="Day", loc="upper left", fontsize=12)
plt.show()
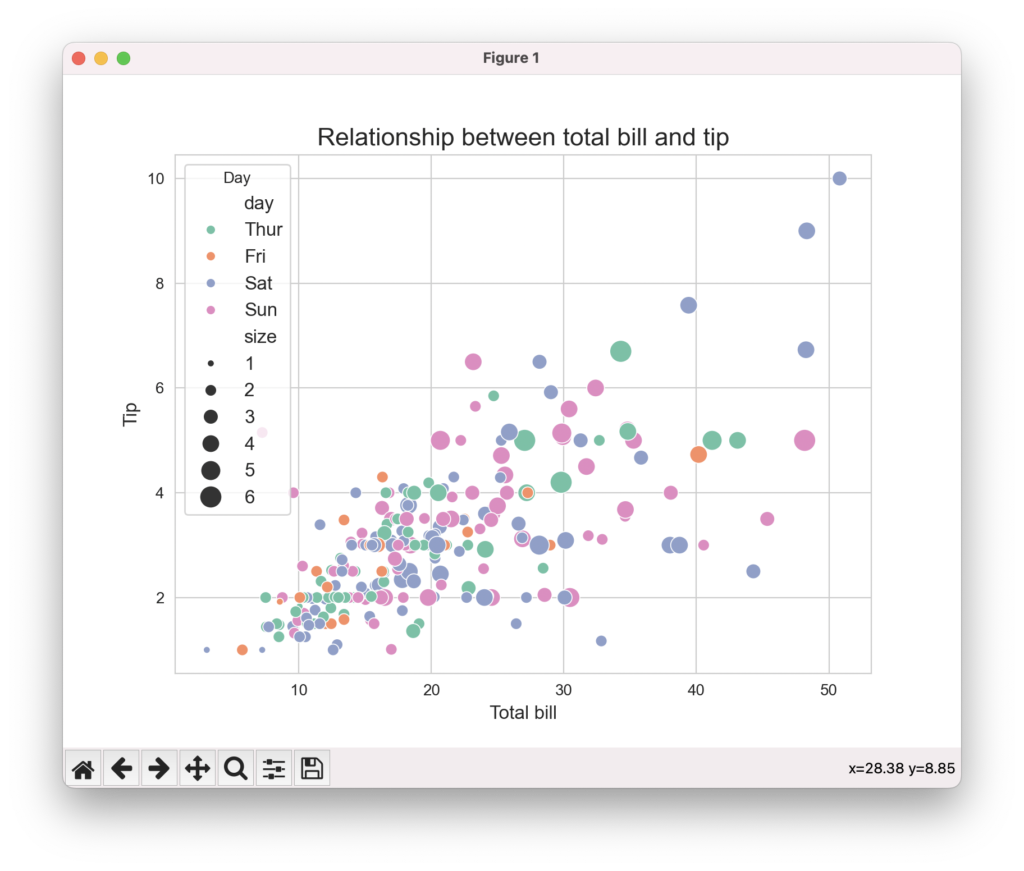
seabornのプロットを使いこなすことで、データの特徴や傾向を視覚的に表現し、インサイトを引き出すことができます。状況に応じて適切なプロットを選択し、データストーリーを効果的に伝えるビジュアライゼーションを作成しましょう。次章では、seabornを使いこなすためのコツとデータビジュアライゼーションのベストプラクティスを紹介します。
まとめ:seabornを使いこなすコツとデータビジュアライゼーションのベストプラクティス
seabornは、美しく洗練されたデータビジュアライゼーションを手軽に作成できる強力なツールです。一方で、seabornをブラックボックス的に使うのではなく、その仕組みや特性を理解することが大切です。データの特徴を適切に表現できるプロットを選択し、必要に応じてカスタマイズしましょう。
また、ビジュアライゼーションの目的を明確にし、伝えたいメッセージを絞り込むことが重要です。デザインの一貫性、シンプルさ、読みやすさに配慮し、ノイズを最小限に抑えましょう。インタラクティブな操作を取り入れることで、データ探索の幅を広げることもできます。
グラフを適切にラベリングし、必要な情報を過不足なく提示することも忘れてはいけません。色使いに気をつけ、色覚多様性にも配慮しましょう。さらに、ビジュアライゼーションを通して得られた知見を言語化し、ストーリーを伝える力を養うことも大切です。
seabornを使うメリットと注意点
seabornは、高品質のデータビジュアライゼーションをシンプルなコードで実現できるライブラリです。デフォルトの設定が洗練されているため、初心者でも美しいグラフを作成できます。統計解析に特化したプロットが豊富で、データサイエンスのタスクに適しています。また、グラフのデザインを柔軟にカスタマイズでき、ニーズに合わせた調整が可能です。ドキュメントが充実しており、体系的に学習できるのも魅力の一つです。
一方で、seabornは高レベルなインターフェースのため、細かな制御は難しい場合があります。デフォルトのスタイルに頼りすぎると、画一的な印象を与えるおそれもあります。さらに、seabornの内部動作を理解せずに使うと、グラフの意味を誤解する危険性もあるので注意が必要です。
魅力的で説得力のあるデータビジュアライゼーションのポイント
魅力的で説得力のあるデータビジュアライゼーションを作成するには、いくつかのポイントを押さえておくことが重要です。まず、データビジュアライゼーションの目的を明確にし、その目的に沿ったグラフを選択しましょう。データの特性や構造を理解し、適切な前処理を行うことも欠かせません。
グラフの種類や設定を吟味し、データの特徴を効果的に表現しましょう。シンプルで直感的なデザインを心がけ、不要な装飾は控えめにします。色使いに意味を持たせ、配色のバランスにも配慮が必要です。タイトル、軸ラベル、凡例などを適切に設定し、グラフを自己説明的にすることも大切です。
インタラクティブ性を取り入れ、ユーザーの能動的なデータ探索を促すのも効果的です。データの文脈や背景情報も提供し、ストーリーを伝えることを意識しましょう。常に客観的な視点を保ち、データを誠実に扱うことが求められます。
ビジュアライゼーションのベストプラクティスを学び、継続的に技術を磨くことも重要です。seabornを適切に活用し、そのメリットを最大限に引き出しながら、魅力的で説得力のあるデータビジュアライゼーションを作成しましょう。
本記事では、Pythonのデータ可視化ライブラリseabornについて、その概要や特徴、基本的な使い方から、実践的なデータ可視化テクニックまで幅広く解説してきました。seabornを使いこなすことで、データの持つメッセージを効果的に伝えるビジュアライゼーションを作成できます。
ただし、seabornはあくまでツールの一つであり、データビジュアライゼーションの真の目的は、データから価値ある知見を引き出し、それを適切に伝えることにあります。seabornを活用しながら、データ分析の原則とベストプラクティスを常に意識し、探索的なデータ分析と説得力のあるストーリーテリングを実践していきましょう。

