

データ分析と機械学習の分野で注目を集めているJupyter Notebook。この記事では、Jupyter Notebookの基礎から応用までを丁寧に解説します。初心者の方にもわかりやすく、実践的なデータ分析のスキルが身につくよう、ステップバイステップでガイドします。Jupyter Notebookを使いこなして、データサイエンスの世界で活躍しましょう!
- Jupyter Notebookの特徴と利点
- Jupyter Notebookのインストール方法と基本的な使い方
- データの読み込み、前処理、可視化、機械学習モデルの構築方法
- 外部ライブラリの活用方法
- Notebookの共有とコラボレーションの方法
- 再現可能な研究のためのJupyter Notebookの活用法
- データサイエンスのキャリアアップに向けたヒント
Jupyter Notebookとは?その特徴と利点
Jupyter Notebookは、データ分析やプログラミングに最適化された対話型の開発環境です。ウェブブラウザ上で動作し、Python、R、Juliaなど複数のプログラミング言語に対応しています。コードの記述、実行、可視化からマークダウンによる説明文の記述までを1つのノートブック上で行えるため、データ分析の過程を効率的に進められます。
Jupyter Notebookの概要と主な機能
Jupyter Notebookの主な機能は以下の通りです:
- コードの記述と実行:セルと呼ばれる単位でコードを記述し、実行結果をすぐに確認できます。これにより、試行錯誤しながらデータ分析を進めることが可能です。
- マークダウンによる文書作成:コードと説明文を交互に記述できるため、データ分析の過程を詳細に記録できます。マークダウン形式で書かれた説明文は、見やすく整形されて表示されます。
- グラフの表示:Matplotlibなどのグラフ描画ライブラリを使って、グラフや図表を直接ノートブック上に表示できます。以下は、サインカーブを描画するサンプルコードです:
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x)
plt.plot(x, y)
plt.title('Sine Wave')
plt.xlabel('x')
plt.ylabel('sin(x)')
plt.show()
- LaTeX形式での数式表示:LaTeX形式で数式を記述することができ、複雑な数式も美しく表示されます。
Jupyter Notebookが支持される理由
Jupyter Notebookが広く支持される理由は以下の通りです:
- インタラクティブな開発環境:コードの実行結果がすぐに確認でき、仮説検証のサイクルを素早く回せます。
- 再現可能な研究:コードと説明文が1つのノートブックにまとめられているため、データ分析の過程を再現しやすくなります。
- 共有と共同作業:ノートブックをHTMLやPDFに変換して共有したり、バージョン管理システムで管理することで、共同作業がしやすくなります。
- 豊富な拡張機能:多数のエクステンションが提供されており、ノートブックの機能を拡張できます。
以上のように、Jupyter Notebookはデータ分析やプログラミングに適した多機能な開発環境です。インタラクティブな操作性、再現性の高さ、共有のしやすさから、データサイエンティストやエンジニアに広く愛用されています。
Jupyter Notebookのインストールと基本的な使い方
Jupyter Notebookを使い始めるには、まずインストールを行う必要があります。インストールには、Anacondaを使う方法、pipを使う方法、Dockerを使う方法の3つがあります。Anacondaを使えば、Jupyter Notebookを含む主要なデータサイエンスパッケージがまとめてインストールされるため、初心者におすすめです。一方、すでにPythonがインストールされている場合は、pip install jupyterコマンドでJupyter Notebookを単独でインストールできます。Dockerを使う方法は、環境設定を簡略化できるため、より上級者向けです。
Jupyter Notebookのインストール方法
Anacondaを使ったインストール方法を紹介します。まず、Anacondaの公式サイトから、自分のOSに合ったインストーラーをダウンロードします。ダウンロードしたインストーラーを実行し、指示に従ってインストールを進めます。インストールが完了したら、ターミナルまたはコマンドプロンプトで以下のコマンドを実行し、Jupyter Notebookが正しくインストールされたことを確認します。
jupyter notebook --version
Notebookの作成と実行の手順
Jupyter Notebookをインストールしたら、次はNotebookを作成し、実行してみましょう。ターミナルまたはコマンドプロンプトでjupyter notebookコマンドを実行すると、Jupyter Notebookが起動します。ウェブブラウザが自動的に開き、Jupyter Notebookのダッシュボードが表示されます。
新しいノートブックを作成するには、ダッシュボードの「New」ボタンをクリックし、使用する言語を選択します。すると、新しいノートブックが作成され、コードを書いたり実行したりできるようになります。
Jupyter Notebookには、コードセルとマークダウンセルの2種類のセルがあります。コードセルにはPythonのコードを書き、マークダウンセルには説明文を書きます。以下は、コードセルとマークダウンセルの例です。
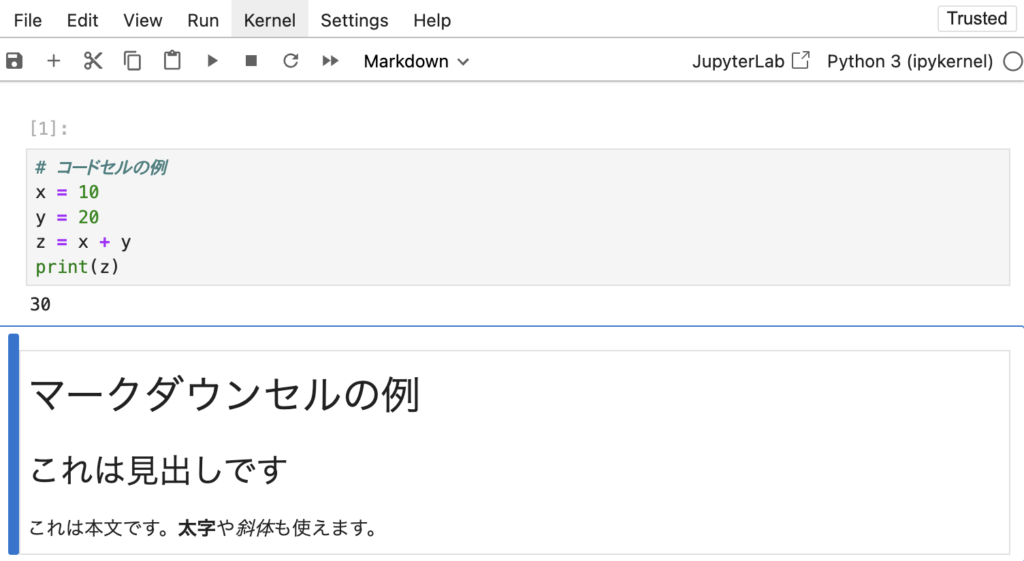
セルを実行するには、セルを選択して「Run」ボタンをクリックするか、Shift+Enterキーを押します。
便利なショートカットキーとTips
Jupyter Notebookには、作業効率を上げるための便利なショートカットキーがたくさんあります。覚えておくと便利なショートカットキーを紹介します。
- Shift + Enter: 現在のセルを実行し、次のセルに移動します。
- Ctrl + Enter: 現在のセルを実行し、同じセルにとどまります。
- Alt + Enter: 現在のセルを実行し、直下に新しいセルを挿入します。
- Tab: コード補完機能を起動します。
- Shift + Tab: 関数のドキュメントを表示します。
また、セルをマークダウンセルに変換したり、新しいセルを挿入したり、セルを削除したりするショートカットキーもあります。
- Esc + m: 現在のセルをマークダウンセルに変換します。
- Esc + a: 現在のセルの上に新しいセルを挿入します。
- Esc + b: 現在のセルの下に新しいセルを挿入します。
- Esc + d + d: 現在のセルを削除します。
以上のショートカットキーを使いこなせば、Jupyter Notebookでの作業効率が大幅に上がるでしょう。
Jupyter Notebookのインストールと基本的な使い方を覚えれば、データ分析や機械学習の学習を効率的に進められます。ぜひJupyter Notebookを活用して、データサイエンスのスキルを磨いていきましょう。
Jupyter Notebookを使ったデータ分析の実践
Jupyter Notebookは、データ分析のための強力なツールです。データの読み込みや前処理、可視化、機械学習モデルの構築と評価など、データ分析のあらゆる段階をJupyter Notebook上で行うことができます。ここでは、Jupyter Notebookを使ったデータ分析の実践について、具体的なステップを追って説明します。
データの読み込みと前処理
データ分析の第一歩は、データの読み込みと前処理です。Jupyter Notebookでは、pandasライブラリを使ってデータを読み込むことができます。例えば、CSVファイルを読み込むには、pd.read_csv()関数を使います。
import pandas as pd
# データの読み込み
df = pd.read_csv('data.csv')
データを読み込んだら、次は前処理です。前処理では、データの統計量の確認、欠損値の処理、データ型の変換などを行います。以下は、それぞれの処理の例です。
# 統計量の確認 print(df.describe()) # 欠損値の確認と削除 print(df.isnull().sum()) df = df.dropna() # データ型の変換 df['カラム名'] = df['カラム名'].astype(int)
データの可視化とグラフの作成
前処理が終わったら、データの可視化に移ります。可視化では、データの傾向や特徴を視覚的に把握することができます。Jupyter Notebookでは、matplotlibやseabornといったライブラリを使ってグラフを作成できます。
以下は、matplotlibを使った線グラフの作成例です。
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
plt.plot(df['x'], df['y'])
plt.title('Line Plot')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
seabornを使えば、より見栄えの良いグラフを作成できます。以下は、seabornを使った散布図の作成例です。
import seaborn as sns
sns.scatterplot(data=df, x='x', y='y')
plt.title('Scatter Plot')
plt.show()
機械学習モデルの構築と評価
データの可視化が終わったら、いよいよ機械学習モデルの構築と評価です。Jupyter Notebookでは、scikit-learnライブラリを使ってモデルを構築し、評価することができます。
以下は、線形回帰モデルの構築と評価の例です。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの構築と学習
model = LinearRegression()
model.fit(X_train, y_train)
# 予測と評価
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse:.2f}')
このように、データの分割、モデルの構築と学習、予測と評価といった一連の流れをJupyter Notebook上で実行できます。
以上が、Jupyter Notebookを使ったデータ分析の実践の流れです。データの読み込みと前処理、可視化、機械学習モデルの構築と評価といった一連の過程をJupyter Notebook上で行うことで、データ分析をスムーズに進められます。ぜひJupyter Notebookを活用して、データ分析のスキルを磨いていきましょう。
Jupyter Notebookの応用的な使い方
Jupyter Notebookは、データ分析や機械学習のためのツールとしてだけでなく、より応用的な使い方もできます。ここでは、外部ライブラリの活用方法、Notebookの共有とコラボレーション、再現可能な研究への応用について説明します。
外部ライブラリの活用方法
Jupyter Notebookでは、多様な外部ライブラリを活用することで、データ分析や機械学習のタスクを効率的に行うことができます。以下は、よく使われる外部ライブラリの例です。
- NumPy: 高速な数値計算を行うためのライブラリ。大規模な配列や行列の計算に用いられます。
import numpy as np arr = np.array([[1, 2, 3], [4, 5, 6]]) print(arr)
- Pandas: データ操作とデータ分析のためのライブラリ。データフレームを使ったデータの加工や集計に用いられます。
import pandas as pd
df = pd.read_csv('data.csv')
print(df.head())
- Matplotlib: グラフの描画とデータの可視化のためのライブラリ。様々なグラフや図を作成できます。
import matplotlib.pyplot as plt x = [1, 2, 3, 4, 5] y = [2, 4, 6, 8, 10] plt.plot(x, y) plt.show()
- Seaborn: Matplotlibを基礎としたデータ可視化ライブラリ。より美しく、わかりやすいグラフを作成できます。
import seaborn as sns sns.scatterplot(data=df, x='x', y='y') plt.show()
- Scikit-learn: 機械学習のためのライブラリ。分類、回帰、クラスタリングなどの機械学習アルゴリズムを提供します。
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train)
これらのライブラリを活用することで、Jupyter Notebook上でデータ分析や機械学習のタスクを効率的に行うことができます。
Notebookの共有とコラボレーション
Jupyter Notebookは、他のユーザーとNotebookを共有し、コラボレーションを行うことができます。以下は、Notebookの共有とコラボレーションの方法です。
- Notebookのダウンロード: Notebookをipynbファイルとしてダウンロードし、他のユーザーと共有できます。
- Notebookの変換: Notebookを静的なHTMLやPDFなどのファイル形式に変換し、閲覧しやすくできます。
- GitHubとの連携: GitHubリポジトリとJupyter Notebookを連携させ、バージョン管理やコラボレーションを行えます。
- バインダー: Notebookをクラウド上で実行できるようにするサービスです。共有したNotebookを他のユーザーがすぐに実行できます。
これらの方法を活用することで、Notebookを他のユーザーと共有し、コラボレーションを行うことができます。
Jupyter Notebookを使った再現可能な研究
Jupyter Notebookは、再現可能な研究を行うためのツールとしても活用できます。再現可能性を確保することは、研究結果の信頼性を高めるために不可欠です。
- Notebookによる再現性の向上: Notebookにコードと説明を記述することで、研究の手順や結果を詳細に記録し、再現性を高められます。
- Dockerとの連携: Dockerを使ってNotebookの実行環境を構築することで、他のユーザーが同じ環境を再現しやすくなります。
- MyBinderの活用: MyBinderを使えば、GitHubリポジトリ上のNotebookを誰でもクラウド上で実行できるようになります。
これらの方法を活用することで、Jupyter Notebookを使った再現可能な研究を行うことができます。
以上が、Jupyter Notebookの応用的な使い方の例です。外部ライブラリの活用、Notebookの共有とコラボレーション、再現可能な研究への応用など、Jupyter Notebookの可能性は多岐にわたります。ぜひこれらの応用的な使い方を活用して、より高度なデータ分析や研究を行ってみてください。
まとめ:Jupyter Notebookでデータ分析スキルを磨こう
Jupyter Notebookは、データ分析や機械学習を行うための強力なツールであり、そのメリットを活かしてスキルアップを図ることが重要です。ここでは、Jupyter Notebookのメリットと学習の重要性、およびデータサイエンスのキャリアアップに向けたヒントを紹介します。
Jupyter Notebookのメリットと学習の重要性
Jupyter Notebookには、以下のようなメリットがあります。
- インタラクティブな開発環境:コードの実行結果をすぐに確認できるため、試行錯誤しながらデータ分析を進められます。
- ドキュメンテーションの容易さ:コードと説明を一緒に記述できるため、分析の過程やその理由を詳細に記録できます。
- 再現性の向上:分析に使ったデータやコードなどが全て記録されるため、分析結果の再現性が高まります。
これらのメリットを活かすためには、Jupyter Notebookを使いこなすための学習が欠かせません。オンラインチュートリアルや書籍などの学習リソースを活用して、効率的に学習を進めましょう。
また、学習した内容を実践に活かすことも重要です。以下は、Jupyter Notebookを使ったデータ分析の例です。
import pandas as pd
import matplotlib.pyplot as plt
# データの読み込み
df = pd.read_csv('data.csv')
# データの前処理
df = df.dropna()
df['value'] = df['value'].astype(float)
# データの可視化
plt.figure(figsize=(8, 6))
plt.plot(df['date'], df['value'])
plt.title('Time Series Plot')
plt.xlabel('Date')
plt.ylabel('Value')
plt.show()
このように、Jupyter Notebookを使ってデータの読み込みや前処理、可視化などを行うことで、データ分析のスキルを実践的に身につけられます。
データサイエンスのキャリアアップに向けて
データサイエンスの分野でキャリアアップを目指すためには、以下のようなポイントを押さえておくことが重要です。
- データサイエンスのスキル:プログラミング、統計学、ドメイン知識など、様々なスキルが必要とされます。Jupyter Notebookを使いこなせるようになることは、これらのスキルを身につける第一歩となります。
- ポートフォリオの作成:Jupyter Notebookを使って分析したプロジェクトをポートフォリオとしてまとめ、GitHubなどで公開することで、自分のスキルをアピールできます。
- コミュニティへの参加:Kaggleなどのデータサイエンスコンペティションに参加したり、勉強会やカンファレンスに参加したりすることで、コミュニティとの交流を深められます。
データサイエンスのキャリアパスには、データサイエンティスト、機械学習エンジニア、データアナリストなど、様々な選択肢があります。それぞれのキャリアパスで求められるスキルセットを理解し、目標に向けて学習を進めていきましょう。
Jupyter Notebookを活用してデータ分析のスキルを磨き、データサイエンスの世界で活躍することを目指してみてはいかがでしょうか。本記事で紹介した内容を参考に、まずはJupyter Notebookに慣れることから始めてみましょう。データサイエンスの世界があなたを待っています!

