

自然言語処理ライブラリspacyは、Pythonで高速かつ使いやすい言語処理を実現します。本記事では、spacyの概要から実践的な活用法まで、サンプルコードを交えながら詳しく解説します。自然言語処理の可能性を広げるspacyの魅力を、ぜひ体感してください。
- spacyの特徴と自然言語処理ライブラリとしての位置づけ
- spacyのインストール方法と基本的な使い方
- 日本語テキストの前処理と言語解析の流れ
- テキスト分類、感情分析、キーワード抽出など実践的なユースケース
- 大規模言語モデル(BERT、GPTなど)とspacyを組み合わせた高度な活用法
spacyとは何か?自然言語処理ライブラリの概要と特徴
spacyの位置づけ – 自然言語処理ライブラリの中での立ち位置
spacyは、Pythonで実装された最先端の自然言語処理ライブラリです。他のライブラリと比べると、処理速度と使いやすさに重点を置いているのが特徴です。
高速性を実現するために、spacyはCython(CとPythonのハイブリッド言語)をベースに開発されています。大規模なテキストデータを扱う際に、その真価を発揮します。
また、spacyは機械学習を用いた高度な言語解析を、比較的少ないコード量で実現できます。そのため、研究者だけでなく、実務で言語データを扱うエンジニアやデータサイエンティストにも適しているといえるでしょう。
spacyの特長 – 高速性、設計の柔軟性、充実したモデル等
spacyの大きな特長は、モジュール化された設計にあります。必要な機能だけを選択して使用できるため、無駄なオーバーヘッドを削減できます。また、カスタムコンポーネントを追加することも容易で、開発者の自由度が高いのも魅力の一つです。
spacyには、事前学習済みの言語モデルが豊富に用意されています。英語をはじめ、日本語、中国語、ドイツ語など、多言語に対応。グローバルなプロジェクトにも活用できます。
APIの設計も、シンプルで直感的な使いやすさを重視しています。自然言語処理の複雑な処理を、少ないコード量で実現可能です。
さらに、spacyはオープンソースプロジェクトとしてGitHub上で開発されており、世界中の開発者がコントリビュートしています。活発なコミュニティによって、常に最新の技術を取り込みながら進化を続けている点も、大きな強みといえるでしょう。
spacyのインストールと基本的な使い方
開発環境の準備 – PythonとPipのセットアップ
spacyを使うには、まずPython環境を整える必要があります。spacyは、Python 3.6以上でサポートされています。
Pythonのディストリビューションとして、AnacondaやMiniCondaがおすすめです。これらを使うことで、必要なライブラリのインストールや仮想環境の構築が簡単になります。
Pythonのインストールが完了したら、spacyを動かすためのツールを揃えましょう。JupyterNotebookやJupyterLabがあれば、対話的にspacyのコードを実行しながら動作を確認できるので便利です。
spacyのインストール – Pipコマンドによる導入方法
開発環境が整ったら、いよいよspacyのインストールです。spacyは、Pythonのパッケージ管理システムであるpipを使って導入できます。
ターミナルやコマンドプロンプトから、以下のコマンドを実行してください。
pip install spacy
これだけで、spacyとその依存ライブラリがインストールされます。
Language Modelのダウンロード – 利用可能な言語モデルの種類と入手法
spacyでは、各言語の特徴を学習済みのLanguage Modelを使用します。これらのモデルは、あらかじめspacyが提供している「事前学習済みモデル」をダウンロードすることで利用可能になります。
例えば英語の場合、以下のコマンドでダウンロードできます。
python -m spacy download en_core_web_sm
日本語なら、以下のコマンドになります。
python -m spacy download ja_core_news_sm
このように、使用したい言語のモデルを指定してダウンロードしてください。spacyは100以上の言語に対応しているので、多言語環境で活躍できるでしょう。
spacyの基本的なワークフロー – パイプラインの構成要素と処理の流れ
spacyによる自然言語処理は、以下のようなワークフローで進みます。
- Language Modelを読み込み、nlpオブジェクトを作成する。
- 解析対象のテキストをnlpオブジェクトに渡し、Docオブジェクトを得る。
- DocオブジェクトからTokenオブジェクトを取り出し、単語や品詞の情報にアクセスする。
- 必要に応じて、固有表現の抽出や構文解析などの処理を行う。
これらの一連の処理は、spacyのLanguage Pipelineに沿って実行されます。パイプラインは、Tokenizer、Tagger、Parser、EntityRecognizerなどのコンポーネントで構成されており、テキストデータはこれらのコンポーネントを順に通過していきます。
各コンポーネントの処理結果は、Doc、Token、Spanなどのオブジェクトに格納されます。これらのオブジェクトを通じて、抽出された言語的特徴にアクセスできるようになります。
以上が、spacyを使った自然言語処理の基本的な流れです。次章からは、実際にコードを書きながらspacyの使い方を見ていきましょう。
日本語テキストの前処理と言語解析の基本
Tokenizerによる単語分割 – 日本語特有の問題と対処法
日本語のテキストを解析する際、最初のハードルとなるのがTokenization(単語分割)です。英語などのように単語間にスペースがある言語と異なり、日本語は単語が連続して書かれるため、単語の境界を見つけるのが難しくなります。
spacyの日本語モデルでは、この問題に対処するためにSudachiPyとMeCabをバックエンドとしたTokenizerを提供しています。これらのTokenizerは、日本語の文法的な特徴を考慮しながら、適切な単位で単語を分割してくれます。
ただし、日本語特有の問題として、複合語の分割や未知語の処理などが挙げられます。例えば、「東京都庁」のような複合語を「東京」「都」「庁」のように分割してしまうと、本来の意味が失われてしまいます。
これらの問題に対処するには、ユーザー定義辞書を用いたり、複合語を1つのトークンとして扱うルールを設定したりするのが有効です。spacyでは、Tokenizer.add_special_caseメソッドを使って、このようなカスタマイズができます。
品詞タグ付けとレンマ化 – 単語の標準形・見出し語への変換
単語分割が完了したら、各トークンに品詞情報を付与していきます。これをPOS Tagging(品詞タグ付け)と呼びます。
spacyのTaggerは、日本語ではUniDic品詞体系に基づいてタグ付けを行います。UniDicは、言語学的に精緻な品詞情報を提供しているため、高度な言語解析に適しています。
品詞タグ付けと並行して、レンマ化(Lemmatization)も行われます。レンマ化とは、各トークンを原形(辞書形)に変換する処理です。例えば、動詞の「食べる」「食べた」「食べます」などは、全て原形の「食べる」に変換されます。
これらの処理によって、テキストデータは言語的に整理された形になります。以下のコード例を見てみましょう。
import spacy
nlp = spacy.load("ja_core_news_sm")
doc = nlp("私はリンゴを食べます。")
for token in doc:
print(token.text, token.pos_, token.lemma_)
出力結果は以下のようになります。
私 PRON 私 は ADP は リンゴ NOUN リンゴ を ADP を 食べ VERB 食べる ます AUX ます 。 PUNCT 。
各トークンに対して、品詞タグ(token.pos_)とレンマ(token.lemma_)が付与されていることがわかります。
構文解析 – 単語の係り受け関係の解析
品詞タグ付けが完了したら、次は構文解析(Parsing)を行います。構文解析は、文の構造を解き明かし、単語間の関係性を見出す処理です。
日本語の構文解析では、主に依存構造解析が用いられます。これは、各単語がどの単語に係っているのかを見つけ出す手法です。
spacyのParserは、トークン間の依存関係を推定し、その結果を有向グラフとして出力します。以下のコードで、構文解析の結果を可視化してみましょう。
import spacy
from spacy import displacy
nlp = spacy.load("ja_core_news_sm")
doc = nlp("私はリンゴを食べます。")
displacy.render(doc, style="dep", jupyter=False, file="dependency_plot.svg")
このコードを実行すると、以下のような依存構造のグラフが表示されます。
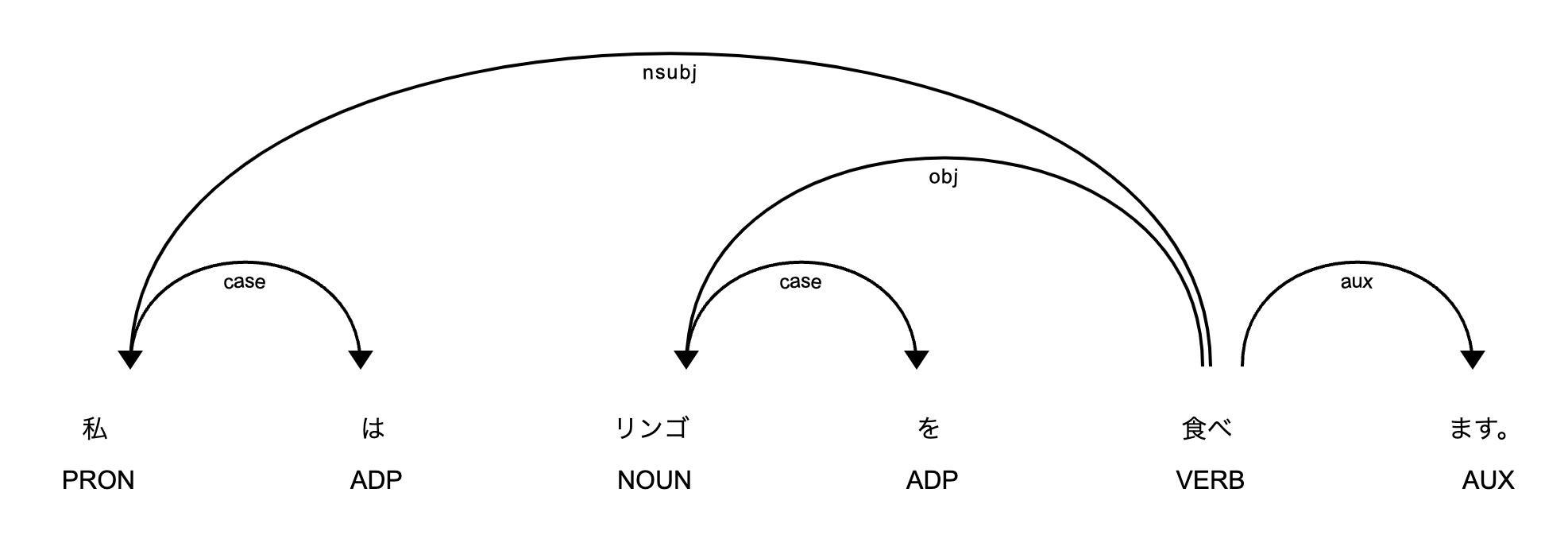
グラフを見ると、「食べます」が文の中心であり、「私」と「リンゴ」がそれに係っていることがわかります。このように、構文解析によって単語間の関係性が明らかになります。
固有表現抽出 – 人名、地名、組織名等の抽出方法
最後に、固有表現抽出(Named Entity Recognition)について見ていきましょう。固有表現抽出は、テキスト中から人名、地名、組織名などの固有名詞を見つけ出す処理です。
spacyのEntityRecognizerは、各言語のモデルに含まれる固有表現データを利用して、テキストから固有表現を抽出します。以下のコードは、日本語テキストから固有表現を見つけ出す例です。
import spacy
nlp = spacy.load("ja_core_news_sm")
doc = nlp("アップル社のティム・クックCEOは、iPhoneの新モデルを発表しました。")
for ent in doc.ents:
print(ent.text, ent.label_)
出力結果は以下のようになります。
アップル社 ORG ティム・クック PERSON iPhone PRODUCT
「アップル社」は組織名、「ティム・クック」は人名、「iPhone」は製品名として認識されています。このように、spacyを使えば簡単に固有表現を抽出できます。
以上、日本語テキストの前処理と基本的な言語解析の手順を見てきました。次章では、これらの技術を応用した実践的なユースケースを紹介していきます。
spacyによる実践的な自然言語処理のユースケース
テキスト分類 – ニュース記事やレビューの自動カテゴリ分類
テキスト分類は、与えられたテキストを予め定義されたカテゴリに振り分ける技術です。ニュース記事のジャンル分類や、レビューの感情極性判定など、幅広い場面で活用されています。
spacyのTextCategorizer機能を使うと、このようなテキスト分類を簡単に実装できます。以下は、ニュース記事をカテゴリ分類する例です。
import spacy
from spacy.tokens import DocBin
# 学習データの準備
train_data = [
("オリンピックの開会式が行われた。", {"cats": {"スポーツ": 1.0, "政治": 0.0, "経済": 0.0}}),
("株価が大幅に下落した。", {"cats": {"スポーツ": 0.0, "政治": 0.0, "経済": 1.0}}),
("首相が記者会見を開いた。", {"cats": {"スポーツ": 0.0, "政治": 1.0, "経済": 0.0}}),
# ...
]
# モデルの学習
nlp = spacy.blank("ja")
textcat = nlp.create_pipe("textcat")
nlp.add_pipe(textcat)
textcat.add_label("スポーツ")
textcat.add_label("政治")
textcat.add_label("経済")
db = DocBin()
for text, annotations in train_data:
doc = nlp(text)
doc.cats = annotations["cats"]
db.add(doc)
db.to_disk("./train.spacy")
nlp.initialize()
nlp.train(db)
# モデルの適用
text = "大統領選挙の投票が始まった。"
doc = nlp(text)
print(doc.cats)
このコードでは、まず学習データを準備します。各テキストに対して、対応するカテゴリを辞書形式で指定します。次に、spacyのモデルを作成し、TextCategorizerコンポーネントを追加します。
学習データをDocBinオブジェクトに変換し、to_disk()メソッドで保存します。そして、nlp.train()でモデルを学習させます。
学習済みモデルを新しいテキストに適用すると、そのテキストがどのカテゴリに属するかが予測されます。doc.catsプロパティに、各カテゴリの確信度が格納されます。
このように、spacyを使えば、大量のテキストを自動的に分類することができます。ニュース記事の自動タグ付けや、レビューの評価分析など、様々な応用が考えられるでしょう。
感情分析 – SNSの投稿などからユーザーの感情を判定する
感情分析は、テキスト中に含まれる感情を数値化する技術です。SNSの投稿やユーザーレビューなどから、書き手の感情を推定するのに役立ちます。
spacyとscikit-learnを組み合わせることで、感情分析器を構築できます。以下は、レビューテキストから感情極性を判定する例です。
import spacy
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
# 学習データの準備
train_data = [
("この製品は最高です!", 1),
("期待はずれでした。二度と買いません。", 0),
("値段の割に良い商品だと思います。", 1),
# ...
]
# 特徴量の抽出
nlp = spacy.load("ja_core_news_sm")
vectorizer = TfidfVectorizer()
texts, labels = zip(*train_data)
X = vectorizer.fit_transform([nlp(text).text for text in texts])
# モデルの学習
model = LogisticRegression()
model.fit(X, labels)
# モデルの適用
text = "良い点もあるけど、もう少し改善の余地がありそう。"
doc = nlp(text)
vec = vectorizer.transform([doc.text])
print(model.predict(vec)[0])
このコードでは、学習データとして、テキストと対応する感情ラベル(1:肯定的、0:否定的)のペアを用意します。
次に、TF-IDFベクトル化を用いて、各テキストを数値ベクトルに変換します。このとき、spacyのモデルを使ってテキストを前処理しておくと、より良い結果が得られるでしょう。
scikit-learnのLogisticRegressionクラスを使って、ロジスティック回帰モデルを学習させます。学習済みモデルに新しいテキストを与えると、そのテキストが肯定的か否定的かを判定してくれます。
このような感情分析器を使えば、SNSユーザーの反応を自動的に集計したり、商品レビューから顧客の満足度を測定したりすることができます。マーケティングや顧客サポートの分野で、大いに活用できるでしょう。
キーワード抽出 – 文書の主題を表す重要語句の同定
キーワード抽出は、テキスト中の主要なトピックを表す語句を自動的に見つけ出す技術です。文書の要約や、検索エンジンの索引付けなどに利用されます。
spacyのDoc.similarity()メソッドを応用することで、簡易的なキーワード抽出が可能です。以下は、その実装例です。
import spacy
from collections import Counter
nlp = spacy.load("ja_core_news_sm")
doc = nlp("自然言語処理は、コンピュータを使って人間の言語を分析し、理解するための技術です。機械翻訳や感情分析など、幅広い応用分野があります。")
# 名詞句のみを抽出
noun_chunks = [chunk.text for chunk in doc.noun_chunks]
# TF-IDFによるスコア付け
word_freq = Counter(noun_chunks)
word_scores = {}
for word in word_freq.keys():
word_doc = nlp(word)
score = 0
for chunk in noun_chunks:
chunk_doc = nlp(chunk)
score += word_doc.similarity(chunk_doc)
word_scores[word] = score / len(noun_chunks)
# スコアの高い上位5件をキーワードとして抽出
keywords = sorted(word_scores.items(), key=lambda x: x[1], reverse=True)[:5]
print(keywords)
このコードでは、まずspacyのDoc.noun_chunksプロパティを使って、文書中の名詞句を抽出します。これにより、重要そうな語句のみを選別できます。
次に、抽出した名詞句について、TF-IDFに似た指標でスコアを計算します。各名詞句と、文書全体との類似度を計算し、その平均値をスコアとします。類似度の計算にはDoc.similarity()メソッドを使用します。
最後に、スコアの高い上位5件の名詞句を、キーワードとして出力します。このようにして、文書の主題を表す語句を自動的に見つけることができます。
キーワード抽出は、大量の文書を要約したり、関連するトピックを探したりする際に威力を発揮します。spacyを使えば、シンプルな方法で キーワードを抽出できるでしょう。
類似度判定 – 文章同士の意味的な近さを測る
類似度判定は、2つの文章がどれだけ似ているかを数値化する技術です。文書検索や、重複コンテンツの検知などに応用できます。
spacyのDoc.similarity()メソッドを使うと、文章間の類似度を簡単に計算できます。以下は、その実装例です。
import spacy
nlp = spacy.load("ja_core_news_sm")
doc1 = nlp("自然言語処理は、人工知能の一分野です。")
doc2 = nlp("自然言語処理は、コンピュータを使って人間の言語を分析する技術です。")
doc3 = nlp("機械学習は、データからパターンを学習することで、未知のデータを予測する手法です。")
print(doc1.similarity(doc2))
print(doc1.similarity(doc3))
このコードでは、3つの文章をspacyのnlpオブジェクトに渡して、Docオブジェクトに変換します。そして、Doc.similarity()メソッドを使って、文章間の類似度を計算します。
類似度は0から1までの値を取り、1に近いほど類似度が高いことを表します。上記の例では、doc1とdoc2の類似度は比較的高く、doc1とdoc3の類似度は低くなっています。
この類似度判定は、spacyの言語モデルが持つ単語ベクトルを利用しています。単語ベクトルは、各単語の意味を多次元空間上の点として表現したものです。文章の類似度は、その文章に含まれる単語ベクトルの平均値同士のコサイン類似度として計算されます。
類似度判定を応用すれば、与えられた文章と似た内容の文章を大量のデータの中から探し出したり、重複する記事を自動的に削除したりすることができるでしょう。
以上、spacyによる実践的な自然言語処理のユースケースを4つ紹介しました。テキスト分類、感情分析、キーワード抽出、類似度判定など、それぞれ強力な機能を備えています。
これらの技術を使いこなすことで、大量のテキストデータから価値ある情報を効率的に引き出せるはずです。次章では、さらに高度なトピックとして、大規模言語モデルとspacyを組み合わせた活用法を探ります。
発展的な話題 – 大規模言語モデルとspacyの連携
BERT、GPT等の事前学習済みモデルの活用法
近年、自然言語処理の分野では、BERT、GPTなどの大規模言語モデルが大きな注目を集めています。これらのモデルは、大量のテキストデータを用いて事前学習された深層学習モデルであり、様々なタスクに転用できる汎用的な言語理解能力を持っています。
大規模言語モデルの特徴は、文脈を考慮した高度な言語理解が可能な点にあります。例えばBERTは、単語の周辺情報から単語の意味を推定する「Masked Language Model」と、文章のつながりを予測する「Next Sentence Prediction」という2つのタスクで学習されています。これにより、単語の意味だけでなく、文章全体の文脈も考慮した言語理解が可能になります。
また、GPTは大量のテキストデータを用いて言語モデルを学習することで、人間のような自然な文章を生成できるようになりました。この生成能力は、質問応答や要約、翻訳など、様々なタスクに応用可能です。
これらの大規模言語モデルを活用することで、spacyによる自然言語処理の精度を大幅に向上させられます。例えば、固有表現抽出における曖昧性の解消や、感情分析における文脈の考慮など、様々な場面で大規模言語モデルの力を借りることができるでしょう。
以下は、BERTを使った感情分析の例です。
import spacy
from transformers import pipeline
nlp = spacy.load("ja_core_news_sm")
analyzer = pipeline("sentiment-analysis", model="使いたいモデル名", tokenizer="daigo/bert-base-japanese-sentiment")
doc = nlp("この映画は最高でした!感動して涙が止まりませんでした。")
for sent in doc.sents:
result = analyzer(sent.text)[0]
print(sent.text, result["label"], result["score"])
このコードでは、spacyを使って文章を文単位に分割し、各文をBERTベースの感情分析器に渡しています。分析結果は、ラベル(”ポジティブ” または “ネガティブ”)とスコア(確信度)で返されます。
これは、spacyとTransformersライブラリを組み合わせた一例ですが、このような形で大規模言語モデルの機能をspacyに取り込むことができます。
Transformersライブラリとの連携によるモデルの高度化
大規模言語モデルを扱う上で欠かせないのが、Transformersライブラリです。TransformersはBERTやGPTなどの事前学習済みモデルを簡単に利用するためのPythonライブラリで、spacyとの親和性も高くなっています。
Transformersを使えば、大規模言語モデルのファインチューニングを行い、タスク特化型のモデルを作成することができます。例えば、商品レビューの感情分析用にBERTをファインチューニングすれば、より高精度な分析が可能になるでしょう。
また、Transformersのpipelinesという機能を使えば、spacyの言語処理パイプラインに大規模言語モデルを組み込むこともできます。以下は、固有表現抽出にBERTを利用する例です。
import spacy
from transformers import pipeline
nlp = spacy.load("ja_core_news_sm")
ner_pipe = pipeline("ner", model="使いたいモデル名", aggregation_strategy="simple")
def bert_ner(doc):
ents = []
for ent in ner_pipe(doc.text):
start = doc.char_span(ent["start"], ent["end"])
if start is None:
continue
ents.append(spacy.tokens.Span(doc, start.i, start.i + 1, label=ent["entity"]))
doc.ents = ents
return doc
nlp.add_pipe(bert_ner)
doc = nlp("夏目漱石の代表作である坊っちゃんは、明治時代を舞台にした物語です。")
for ent in doc.ents:
print(ent.text, ent.label_)
このコードでは、spacyのパイプラインにbert_ner関数を追加しています。この関数は、Transformersのner pipelineを使って固有表現を抽出し、その結果をspacyのSpanオブジェクトに変換しています。
これにより、spacyの通常の固有表現抽出器とBERTベースの抽出器を組み合わせることができ、より高度な抽出が可能になります。
このように、Transformersライブラリとspacyをうまく連携させることで、大規模言語モデルの恩恵を最大限に受けることができるのです。
自然言語処理の分野では、大規模言語モデルの登場によって、新しい可能性が次々と開かれています。これらのモデルをspacyと組み合わせることで、より高度で実用的な言語処理システムを構築できるでしょう。
是非、大規模言語モデルとspacyを組み合わせて、自然言語処理の新たな地平を切り開いてみてください。
まとめ – 最新のspacyで自然言語処理の可能性を広げよう
spacyがもたらす自然言語処理の民主化
本記事では、Pythonの自然言語処理ライブラリであるspacyについて、その概要から実践的な応用まで、幅広く解説してきました。
spacyは、高速で効率的な言語処理を実現するだけでなく、シンプルで直感的なAPIを提供することで、自然言語処理をより身近なものにしています。専門的な知識がなくても、少ないコード量で高度な言語処理を実装できるのは、spacyの大きな魅力と言えるでしょう。
また、事前学習済みの言語モデルを豊富に提供していることも、spacyの強みの一つです。多言語対応も進んでおり、日本語を含む100以上の言語で、高精度な解析が可能になっています。
こうしたspacyの特長は、自然言語処理の民主化に大きく貢献しています。これまで、専門家の領域だった言語処理の技術が、spacyを通じて多くの開発者やデータサイエンティストの手に届くようになったのです。
実務や研究へのspacyの活用アイデア
spacyの活用法は、実に多岐にわたります。本記事で紹介したテキスト分類や感情分析、キーワード抽出などは、その一部に過ぎません。
例えば、ニュース記事の自動カテゴリ分類や、SNSの投稿から企業イメージを分析するなど、ビジネスの現場でもspacyは大いに力を発揮するでしょう。また、学術研究の分野でも、文献の要約や引用関係の解析など、spacyを応用できる場面は数多くあります。
さらに、チャットボットや音声アシスタントの開発にもspacyは活用できます。ユーザーの発話を解析し、適切な応答を生成する際に、spacyの言語理解の機能が大きな助けになるはずです。
このように、spacyは自然言語処理のあらゆる場面で活躍の可能性を秘めています。みなさんも、spacyを使って斬新なアイデアを実現してみてはいかがでしょうか。
spacyの今後の発展への期待
spacyは現在も活発に開発が続けられており、常に新しい機能が追加されています。特に、大規模言語モデルとの連携は、今後ますます重要になってくるでしょう。
BERTやGPTなどの言語モデルを取り込むことで、spacyの言語理解の精度は飛躍的に向上します。これにより、より複雑で高度な自然言語処理タスクへの挑戦が可能になるはずです。
また、spacyのコミュニティも年々拡大しており、世界中の開発者がスキルやノウハウを共有しています。こうした知見の蓄積が、spacyのさらなる発展を後押ししていくことでしょう。
自然言語処理の分野は、めまぐるしい速さで進化を続けています。そんな中にあって、spacyは開発者に寄り添い、言語処理の最前線を切り拓くツールであり続けるでしょう。
spacyの未来に大いに期待し、本記事の内容が読者のみなさんにとって、有益な情報となることを願っています。それでは、spacyを使った自然言語処理の世界を、ぜひ自分の手で体験してみてください。新たな発見と可能性が、きっとそこにあるはずです。

