

Pythonを使った地理空間データ分析に欠かせないライブラリ「geopandas」。本記事では、geopandasの基本的な使い方から、実践的な活用例、発展的なTipsまでを網羅的に解説します。初心者からベテランまで、geopandasでより効果的に地理空間データを扱うための知識とテクニックが満載です。
- geopandasの概要と特徴
- geopandasのインストール方法
- シェープファイルの読み込みと基本的な操作
- ポイントデータ、ラインデータ、ポリゴンデータの可視化
- 空間結合を使ったデータの分析
- データのグループ化と集計
- 距離計測とバッファ分析
- 国土数値情報の利用方法
- foliumと連携したインタラクティブな地図の作成
- 実践的なgeopandasの活用例
- geopandasのメリット・デメリットと他のGISツールとの違い
- 発展的なgeopandasの使い方とTips
目次
- geopandasとは?Pythonユーザーなら知っておくべき地理空間データ分析ツール
- geopandasのインストールからデータのインポートまで。環境構築を詳しく解説
- geopandasでシェープファイルを扱う方法。基本的な操作を一挙に紹介!
- geopandasでポイントデータ、ラインデータ、ポリゴンデータを可視化する方法
- geopandasを使った空間結合の方法。複数のデータを組み合わせて分析しよう
- pandasユーザーならすぐにできる!geopandasを使ったデータ集計
- geopandasを使った距離計測のやり方。バッファ分析にも応用できる
- 国土数値情報をgeopandasで扱う。公共データを地図上に可視化する
- foliumと連携してインタラクティブな地図を作る方法
- 業務で使える!geopandasの実践的な活用例10選
- geopandasのメリット・デメリット。ArcGISなど他ツールとの違いは?
- geopandasのさらに詳しい使い方。上級者向けTips集
geopandasとは?Pythonユーザーなら知っておくべき地理空間データ分析ツール
geopandasの概要と特徴
geopandasは、Pythonユーザーのための強力な地理空間データ処理・分析ライブラリです。pandasをベースに開発されたgeopandasは、GeoPandasデータ構造を導入することで、幾何学的操作や地図投影など、地理空間データに特化した機能を提供します。
以下は、geopandasの主な特徴です。
- pandasの強力なデータ操作・分析機能を地理空間データに応用可能
- シェープファイル、GeoJSON、WKTなど一般的な地理空間データ形式をサポート
- 直感的でシンプルなAPIにより、地理空間データの処理・分析をスムーズに実行
- fiona、shapely、pyproj、matplotlibなどの地理空間ライブラリと連携し、高度な空間解析を実現
つまり、geopandasを使えば、Pythonの豊富な機械学習やデータ分析ライブラリと組み合わせて、地理空間データを自在に扱うことができるのです。
geopandasを使うメリット
では、なぜ地理空間データ分析にgeopandasを使うべきなのでしょうか。最大のメリットは、以下の3点に集約できます。
- オープンソースで無償利用が可能。商用GISソフトに比べてコストを大幅に削減できる。
- Jupyter Notebookと相性抜群。コードベースでインタラクティブな地理空間データ分析を実現。
- pandasのデータ処理・分析機能と地理空間操作を組み合わせられる。融通の利く高度な分析が可能。
例えば、以下のようなことが簡単にできます。
- 国勢調査のデータをpandasで前処理し、geopandasで都道府県の境界データと結合して、人口分布を視覚化
- GPSログデータから移動軌跡を生成し、道路ネットワークデータを使って最適ルートを解析
- 住所リストをジオコーディングしてポイントデータに変換し、商圏分析や最適立地分析を実行
geopandasとは何か、何ができるツールなのか
geopandasは、地理空間データを扱うすべてのPythonユーザーにとって、必携のライブラリといえるでしょう。Pythonでデータ分析や機械学習に取り組んでいるなら、ぜひ覚えておきたいツールの一つです。
少しでも地理空間データを分析する場面があれば、geopandasを使うことで、効率的で柔軟性の高い開発が可能になります。例えば、以下のようなデータを扱う際に威力を発揮します。
- 緯度経度や住所を含むデータ
- 市区町村、都道府県、国などの境界データ
- 道路、鉄道、河川などのネットワークデータ
- 標高、土地利用、気象などのラスターデータ
サンプルコードを見てみましょう。わずか数行で、シェープファイルの読み込みから地図のプロットまでができてしまいます。
import geopandas as gpd
# シェープファイルの読み込み
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
# 基本情報の確認
print(world.head())
print(world.crs)
# 地図のプロット
world.plot(column='continent', legend=True, figsize=(10, 10))
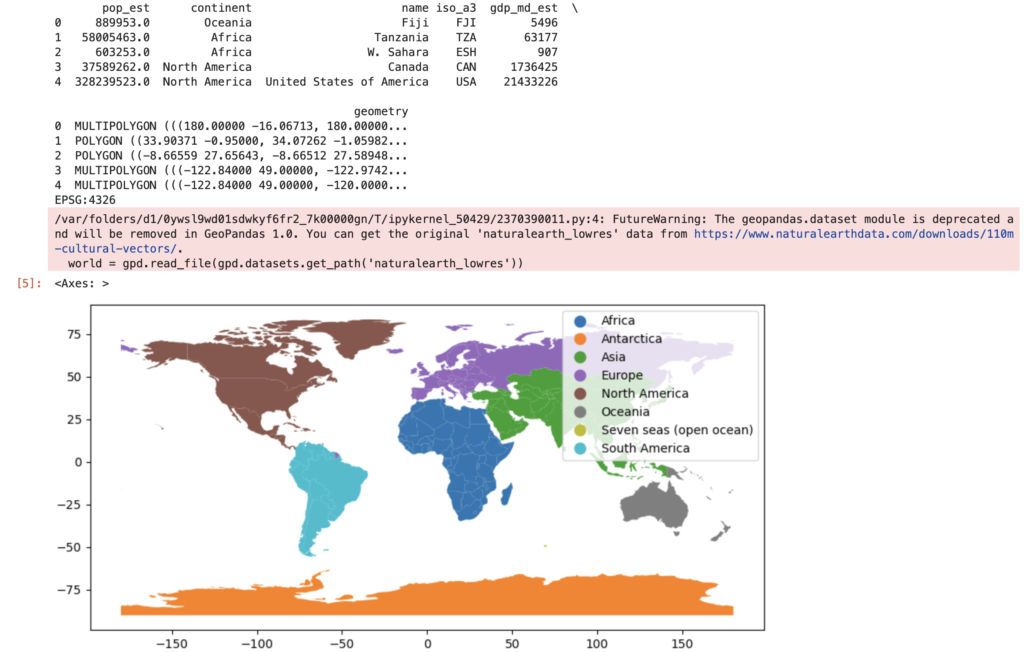
このように、geopandasを使えばPythonで手軽に地理空間データ分析に挑戦できます。研究や実務で地理空間データを使う機会のあるPythonユーザーは、ぜひこの強力なツールを習得してみてください。きっとあなたの開発力とアイデアを大きく広げてくれるはずです。
次章では、geopandasを使える環境を整える方法を詳しく解説します。お楽しみに!
geopandasのインストールからデータのインポートまで。環境構築を詳しく解説
本章では、geopandasを使うための環境構築の方法を解説します。geopandasのインストールには、Anacondaを使う方法とpipを使う方法の2つがあります。それぞれの特徴を理解して、自分に合った方法を選びましょう。
Anacondaを使ったgeopandasのインストール手順
Anacondaは、Pythonでデータサイエンスを行うための包括的なプラットフォームです。geopandasなど主要な地理空間ライブラリが同梱されているため、初心者にもおすすめのインストール方法です。
以下の手順で、Anacondaを使ってgeopandasをインストールします。
- Anacondaをインストールする(https://www.anaconda.com/products/individual)
- Anaconda Promptを開く
- 以下のコマンドで新しい環境を作成し、geopandasをインストールする
conda create -n geo_env conda activate geo_env conda install -c conda-forge geopandas
これで、geopandasを含む地理空間データ分析用の環境が整いました。conda listコマンドで、インストールされたパッケージを確認できます。
pipを使ったgeopandasのインストール手順
pipは、Pythonのパッケージ管理システムです。以下のコマンドを実行することで、geopandasをインストールできます。
pip install geopandas
ただし、geopandasは多くの依存ライブラリを必要とするため、個別にインストールが必要になる場合があります。例えば、fiona, shapely, pyproj, pandas, numpyなどです。エラーが出た場合は、それぞれのライブラリをpip installコマンドでインストールしてください。
また、GDAL, GEOS, Proj4などのライブラリが必要になる場合もあります。これらはPythonではないため、OSのパッケージ管理システムを使ってインストールします。
- macOS:
brew install gdal geos proj - Ubuntu:
sudo apt-get install gdal-bin libgeos-dev proj-bin
サンプルデータのダウンロードとインポート方法
geopandasには、世界地図やニューヨーク市の行政区などのサンプルデータが付属しています。これらのデータを使って、geopandasの基本的な使い方を練習してみましょう。
以下のコードで、サンプルデータを読み込めます。
import geopandas as gpd
# 世界地図データの読み込み
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
# USAの州データの読み込み
NY = gpd.read_file(gpd.datasets.get_path('nybb'))
geopandas.datasetsモジュールには、他にもいくつかのサンプルデータが用意されています。
また、ShapefileやGeoJSONなどの一般的な地理空間データを読み込むには、以下のようにgeopandas.read_file()関数を使います。
# Shapefileの読み込み
data = gpd.read_file('path/to/shapefile.shp')
# GeoJSONの読み込み
data = gpd.read_file('path/to/geojson.json')
geopandasにデータを読み込めば、pandasのデータ操作と組み合わせて、自由自在に地理空間データ分析を進められます。
以上で、geopandasの環境構築とデータインポートの基本が理解できたと思います。次章からは、実際にgeopandasでどのように地理空間データを処理・分析するのか、コードを交えて詳しく解説していきます。
geopandasでシェープファイルを扱う方法。基本的な操作を一挙に紹介!
geopandasで地理空間データ分析を行う上で、最も重要なスキルの一つが、シェープファイルの取り扱い方です。本章では、シェープファイルの読み込みから、属性データの確認、地図へのプロットまでを、実例を交えて解説していきます。
シェープファイルの読み込み方
geopandasでシェープファイルを読み込むには、geopandas.read_file()関数を使います。以下のように、シェープファイルのパスを指定するだけで、簡単にデータを読み込めます。
import geopandas as gpd
# シェープファイルの読み込み
data = gpd.read_file('path/to/shapefile.shp')
読み込まれたデータは、GeoDataFrameというデータ構造に格納されます。GeoDataFrameは、pandasのDataFrameに地理空間情報が追加されたようなものです。
シェープファイルは、複数のファイル(.shp, .dbf, .shxなど)で構成されています。.shpファイルを指定して読み込めば、他のファイルは自動的に読み込まれるので、ファイルの指定は1つだけでOKです。
基本的な属性データの確認方法
シェープファイルには、地物の形状情報だけでなく、属性情報も含まれています。geopandasで読み込んだGeoDataFrameの列には、これらの属性データが格納されています。
以下のように、.head()で先頭のデータを表示したり、.columnsで列名の一覧を確認したりできます。
# 先頭5行を表示 print(data.head()) # 列名の一覧を表示 print(data.columns)
列名がわかれば、DataFrameと同じように列名を指定して、個別の属性データにアクセスできます。
# 'column_name'列の値を表示 print(data['column_name'])
属性データを確認することで、シェープファイルにどのような情報が含まれているのかを把握できます。列の値を集計したり、他のデータと結合したりする際の指標になるでしょう。
シェープファイルを地図上にプロットする
シェープファイルの形状情報を地図上に可視化するには、GeoDataFrameの.plot()メソッドを使います。
# 地図のプロット data.plot(figsize=(10, 10))
これだけで、シェープファイルの形状が地図上にプロットされます。.plot()メソッドには、以下のようなオプションを指定できます。
column: 塗り分けに使う列を指定cmap: カラーマップを指定edgecolor: 境界線の色を指定linewidth: 境界線の太さを指定alpha: 透明度を指定
これらを組み合わせることで、より見やすく情報が伝わる地図を作成できるでしょう。
# columnを指定して塗り分け data.plot(column='column_name', cmap='viridis', edgecolor='white', linewidth=0.5, figsize=(10, 10))
以上が、geopandasでシェープファイルを扱う上での基本操作です。次章では、シェープファイルに含まれるポイントやライン、ポリゴンなどの地物の扱い方を、もっと詳しく見ていきます。
geopandasでポイントデータ、ラインデータ、ポリゴンデータを可視化する方法
geopandasでは、ポイントデータ、ラインデータ、ポリゴンデータなど、様々な地物の種類を扱うことができます。本章では、それぞれのデータ型の特徴と、geopandasでの可視化方法を詳しく解説します。
ポイントデータの可視化
ポイントデータは、店舗の位置情報や事故の発生箇所など、地図上の特定の位置を表すデータです。geopandasでは、shapely.geometry.Pointでポイントデータを表現します。
以下は、ポイントデータを地図上にプロットする例です。
import geopandas as gpd
# ポイントデータの作成
data = gpd.GeoDataFrame(
{'id': [1, 2, 3],
'value': [10, 20, 30]},
geometry=gpd.points_from_xy([1, 2, 3], [1, 2, 3])
)
# ポイントデータの可視化
data.plot(marker='o', markersize=100, column='value', cmap='viridis', figsize=(10, 10))
.plot()メソッドの引数で、ポイントのマーカースタイル(marker)、サイズ(markersize)、色分けに使う列(column)、カラーマップ(cmap)などを指定できます。
ポイントデータは、クラスタリング分析や最近隣分析など、位置情報に基づく分析によく使われます。
ラインデータの可視化
ラインデータは、道路や河川など、線的な形状を表すデータです。geopandasでは、shapely.geometry.LineStringでラインデータを表現します。
以下は、ラインデータを地図上にプロットする例です。
import geopandas as gpd
import shapely
# ラインデータの作成
data = gpd.GeoDataFrame(
{'id': [1, 2],
'value': [10, 20]},
geometry=[
shapely.geometry.LineString([(1, 1), (2, 2)]),
shapely.geometry.LineString([(2, 2), (3, 3)])
]
)
# ラインデータの可視化
data.plot(linewidth=5, color='red', figsize=(10, 10))
.plot()メソッドの引数で、ラインの太さ(linewidth)、色(color)などを指定できます。column引数を指定すれば、ラインの色分けもできます。
ラインデータは、ネットワーク分析や最短経路探索など、線的なつながりを分析する際に活用されます。
ポリゴンデータの可視化
ポリゴンデータは、行政区画や土地利用など、面的な形状を表すデータです。geopandasでは、shapely.geometry.Polygonでポリゴンデータを表現します。
以下は、ポリゴンデータを地図上にプロットする例です。
import geopandas as gpd
# ポリゴンデータの作成
data = gpd.GeoDataFrame(
{'id': [1, 2],
'value': [10, 20]},
geometry=[
shapely.geometry.Polygon([(1, 1), (2, 1), (2, 2), (1, 2)]),
shapely.geometry.Polygon([(2, 2), (3, 2), (3, 3), (2, 3)])
]
)
# ポリゴンデータの可視化
data.plot(edgecolor='black', linewidth=1, column='value', cmap='viridis', figsize=(10, 10))
.plot()メソッドの引数で、ポリゴンの境界線の色(edgecolor)、太さ(linewidth)、塗り分けに使う列(column)、カラーマップ(cmap)などを指定できます。
ポリゴンデータは、面積計算や空間結合、ゾーニングなど、面的な広がりを考慮した分析に利用されます。
以上のように、geopandasを使えば、ポイントデータ、ラインデータ、ポリゴンデータなど、様々な地物を簡単に可視化できます。次章では、これらのデータを組み合わせて分析する方法を見ていきましょう。
geopandasを使った空間結合の方法。複数のデータを組み合わせて分析しよう
空間結合は、2つの地理空間データを空間的な位置関係に基づいて結合する操作です。geopandasでは、.sjoin()メソッドを使って空間結合を行うことができます。本章では、空間結合の概要と、intersects、contains、withinを使った空間結合の方法を詳しく解説します。
空間結合とは
空間結合は、以下のような場面で活用できます。
- ポイントデータとポリゴンデータの結合(ポイントが含まれるポリゴンを特定)
- ラインデータとポリゴンデータの結合(ラインが交差するポリゴンを特定)
- 複数のポリゴンデータの結合(重なり合うポリゴンを特定)
geopandasの.sjoin()メソッドは、以下のような構文で使用します。
result = gpd.sjoin(data1, data2, op='intersects')
data1とdata2は結合する2つのGeoDataFrame、opは結合の条件を指定します。結合した結果は、新しいGeoDataFrameとして返されます。
intersectsを使った空間結合
op='intersects'を指定すると、2つのジオメトリが交差する(重なる)場合に結合されます。
以下は、ポイントデータとポリゴンデータをintersectsで結合する例です。
import geopandas as gpd
# データの読み込み
points = gpd.read_file('points.shp')
polygons = gpd.read_file('polygons.shp')
# intersectsを使った空間結合
result = gpd.sjoin(points, polygons, op='intersects')
# 結果の確認
print(result.head())
結果のGeoDataFrameには、ポイントの属性情報とそれが含まれるポリゴンの属性情報が含まれます。
containsを使った空間結合
op='contains'を指定すると、一方のジオメトリが他方のジオメトリを完全に含む場合に結合されます。
以下は、ポリゴンデータとポイントデータをcontainsで結合する例です。
import geopandas as gpd
# データの読み込み
polygons = gpd.read_file('polygons.shp')
points = gpd.read_file('points.shp')
# containsを使った空間結合
result = gpd.sjoin(polygons, points, op='contains')
# 結果の確認
print(result.head())
結果のGeoDataFrameには、各ポリゴンに含まれるポイントの属性情報が追加されます。
withinを使った空間結合
op='within'を指定すると、一方のジオメトリが他方のジオメトリに完全に含まれる場合に結合されます。
以下は、ポイントデータとポリゴンデータをwithinで結合する例です。
import geopandas as gpd
# データの読み込み
points = gpd.read_file('points.shp')
polygons = gpd.read_file('polygons.shp')
# withinを使った空間結合
result = gpd.sjoin(points, polygons, op='within')
# 結果の確認
print(result.head())
結果のGeoDataFrameには、各ポイントが含まれるポリゴンの属性情報が追加されます。
以上のように、geopandasの空間結合を使えば、複数の地理空間データを空間的な関係性に基づいて結合し、より高度な分析を行うことができます。空間結合は、地理空間データ分析において非常に重要な操作なので、しっかりとマスターしておきましょう。
次章では、geopandasを使ったデータの集計方法を見ていきます。
pandasユーザーならすぐにできる!geopandasを使ったデータ集計
geopandasは、pandasのデータ処理機能を継承しているため、pandasでのデータ集計の知識があれば、geopandasでも同様の処理を行うことができます。本章では、geopandasを使ったデータのグループ化、集計、列の追加などの方法を解説します。
geopandasを使ったデータのグループ化
geopandasの.groupby()メソッドを使うと、特定の列の値に基づいてデータをグループ化できます。以下は、’category’列でデータをグループ化する例です。
import geopandas as gpd
# データの読み込み
data = gpd.read_file('data.shp')
# 'category'列でグループ化
grouped = data.groupby('category')
# グループごとの集計値を計算
result = grouped.agg({'value': 'sum'})
print(result)
.groupby()メソッドの引数に列名を指定することで、その列の値に基づいてグループ化されます。グループ化された結果は、DataFrameGroupByオブジェクトとして返されます。
DataFrameGroupByオブジェクトに対して、.agg()メソッドを使うことで、グループごとの集計値を計算できます。上の例では、’value’列の合計値を計算しています。
geopandasを使ったデータの集計
geopandasのGeoDataFrameに対しては、.sum()、.mean()、.max()、.min()などの集計メソッドを直接適用できます。
import geopandas as gpd
# データの読み込み
data = gpd.read_file('data.shp')
# 全体の合計値を計算
total = data['value'].sum()
print(f"Total value: {total}")
# 'category'列ごとの平均値を計算
mean_by_category = data.groupby('category')['value'].mean()
print("Mean value by category:")
print(mean_by_category)
このように、特定の列を指定して集計することもできます。.groupby()メソッドと組み合わせることで、グループごとの集計値も簡単に計算できます。
列の追加と計算
geopandasのGeoDataFrameに新しい列を追加するには、[]を使って列名を指定し、値を代入します。既存の列を使った計算結果を新しい列として追加することもできます。
import geopandas as gpd
# データの読み込み
data = gpd.read_file('data.shp')
# 新しい列'new_column'を追加
data['new_column'] = 1
# 既存の列'value'を2倍した値を新しい列'double_value'として追加
data['double_value'] = data['value'] * 2
print(data.head())
このように、新しい列の追加や既存の列を使った計算は、pandasと同じ方法で行うことができます。
以上が、geopandasを使ったデータ集計の基本的な方法です。pandasの知識があれば、すぐにgeopandasでもデータ集計ができるようになるでしょう。
ただし、地理空間データの集計では、以下のような点に注意が必要です。
- データの単位や尺度に注意する(面積の単位、人口の単位など)
- 空間的な偏りを考慮した集計方法(例:カーネル密度推定)も検討する
地理空間データの特性を理解した上で、適切な集計方法を選ぶことが重要です。
次章では、geopandasを使った距離の計算方法を見ていきます。
geopandasを使った距離計測のやり方。バッファ分析にも応用できる
geopandasを使えば、ポイント間の距離、ラインの長さ、ポリゴンの面積など、様々な距離計測を簡単に行うことができます。本章では、それぞれの距離計測の方法と、バッファの作成方法を解説します。
ポイント間の距離を計算する
geopandasのGeoSeriesの.distance()メソッドを使うと、ポイント間の距離を計算できます。以下は、各ポイントから最初のポイントまでの距離を計算する例です。
import geopandas as gpd
# データの読み込み
points = gpd.read_file('points.shp')
# ポイント間の距離を計算
distances = points.geometry.distance(points.geometry[0])
print(distances)
.distance()メソッドの引数に、距離を計算するポイントのGeoSeriesを指定します。結果は、各ポイントからの距離を格納したSeriesとして返されます。
ラインの長さを計算する
geopandasのGeoSeriesの.length属性を使うと、ラインの長さを計算できます。
import geopandas as gpd
# データの読み込み
lines = gpd.read_file('lines.shp')
# ラインの長さを計算
lengths = lines.geometry.length
print(lengths)
結果は、各ラインの長さを格納したSeriesとして返されます。
ポリゴンの面積を計算する
geopandasのGeoSeriesの.area属性を使うと、ポリゴンの面積を計算できます。
import geopandas as gpd
# データの読み込み
polygons = gpd.read_file('polygons.shp')
# ポリゴンの面積を計算
areas = polygons.geometry.area
print(areas)
結果は、各ポリゴンの面積を格納したSeriesとして返されます。
バッファの作成方法
geopandasのGeoSeriesの.buffer()メソッドを使うと、ジオメトリの周りにバッファを作成できます。以下は、各ポイントから1000mのバッファを作成する例です。
import geopandas as gpd
# データの読み込み
points = gpd.read_file('points.shp')
# バッファの作成
buffers = points.geometry.buffer(1000)
# バッファの可視化
gpd.GeoSeries(buffers).plot()
.buffer()メソッドの引数に、バッファの距離を指定します。結果は、バッファ領域を表す新しいGeoSeriesとして返されます。
これらの距離計測は、以下のような場面で活用できます。
- ポイント間の距離を使って、最近隣分析や密度分析を行う
- ラインの長さを使って、道路のトータル距離や平均距離を計算する
- ポリゴンの面積を使って、土地利用の比率や人口密度を計算する
- バッファを使って、ポイントの影響範囲を分析する
ただし、距離計測を行う際には、以下の点に注意が必要です。
- 距離の単位に注意する(度、メートル、キロメートルなど)
- 座標系を適切に設定し、距離計算の精度を確保する
特に、座標系の設定は重要です。以下のように、GeoDataFrameの.crs属性を使って、座標系を確認・設定できます。
import geopandas as gpd
# データの読み込み
data = gpd.read_file('data.shp')
# 座標系の確認
print(data.crs)
# 座標系の設定
data = data.set_crs('EPSG:4326')
適切な座標系を設定することで、正確な距離計測が可能になります。
以上が、geopandasを使った距離計測の基本的な方法です。次章では、国土数値情報をgeopandasで扱う方法を見ていきます。
国土数値情報をgeopandasで扱う。公共データを地図上に可視化する
国土数値情報は、国土交通省が提供する国土に関する様々な地理空間情報のデータセットです。行政区域、鉄道、道路、土地利用など、多岐にわたるデータが無償で利用可能であり、国や地方自治体の政策立案、民間企業のビジネス、学術研究などに活用されています。本章では、国土数値情報の概要と、geopandasを使った国土数値情報の利用方法を解説します。
国土数値情報とは
国土数値情報は、以下のような特徴を持っています。
- 国土交通省が提供する信頼性の高い地理空間情報
- 全国をカバーする統一的なデータセット
- 行政区域、交通、自然環境など、様々な分野のデータを提供
- 無償で利用可能(利用規約に同意が必要)
- 様々な地図アプリケーションやGISソフトウェアで利用可能
国土数値情報で提供されているデータの例としては、以下のようなものがあります。
- 行政区域データ
- 鉄道データ
- 道路データ
- 土地利用データ
- 河川データ
- 標高データ
- 公共施設データ
これらのデータを組み合わせることで、様々な分析や可視化が可能になります。
国土数値情報のダウンロード方法
国土数値情報をダウンロードするには、以下の手順を実行します。
- 国土数値情報ダウンロードサービス(https://nlftp.mlit.go.jp/ksj/)にアクセスする。
- 利用規約を確認し、同意する。
- ダウンロードしたいデータを選択し、必要な地域や年度を指定してダウンロードする。
- ダウンロードしたデータを解凍し、シェープファイルなどの地理空間データを取り出す。
国土数値情報の利用規約は、データの種類によって異なる場合があるので、注意が必要です。また、データのファイル形式や座標系、文字コードなどにも注意しましょう。
国土数値情報をgeopandasで読み込む
geopandasを使って、ダウンロードした国土数値情報のシェープファイルを読み込むには、以下のようなコードを使います。
import geopandas as gpd
# 国土数値情報の読み込み
data = gpd.read_file('path/to/kokudo.shp', encoding='CP932')
# 座標系の設定(必要に応じて)
data = data.to_crs('EPSG:4326')
# データの確認
print(data.head())
geopandas.read_file()関数を使って、国土数値情報のシェープファイルを読み込みます。その際、encoding引数で文字コードを指定する必要がある場合があります。国土数値情報の多くは、CP932(Shift-JIS)という文字コードを使用しています。
また、国土数値情報のデータには、座標系の情報が含まれていない場合があります。その場合は、to_crs()メソッドを使って、適切な座標系を設定する必要があります。
以下は、国土数値情報の行政区域データを読み込み、可視化する例です。
import geopandas as gpd
import matplotlib.pyplot as plt
# 行政区域データの読み込み
admin_area = gpd.read_file('file_name.shp', encoding='CP932')
# 座標系の設定
admin_area = admin_area.to_crs('EPSG:4326')
# 可視化
admin_area.plot(figsize=(10, 10), edgecolor='black', facecolor='white', linewidth=0.5)
plt.show()
このように、geopandasを使えば、国土数値情報を簡単に読み込み、分析や可視化に活用できます。国土数値情報は、地理空間データ分析の入門者にとって最適な練習用データセットといえるでしょう。
次章では、geopandasとfoliumを組み合わせて、インタラクティブな地図を作成する方法を見ていきます。
foliumと連携してインタラクティブな地図を作る方法
foliumは、Python用のインタラクティブな地図作成ライブラリです。leaflet.jsをベースにしており、Webブラウザ上で動作します。geopandasと連携することで、地理空間データをインタラクティブな地図上に可視化できます。本章では、foliumの基本的な使い方と、geopandasとの連携方法を解説します。
背景地図の設定
まず、folium.Map()関数を使って、地図のインスタンスを作成します。location引数で地図の中心座標、zoom_start引数で初期ズームレベルを指定します。tiles引数で、背景地図の種類を選択できます。
import folium # 地図の作成 m = folium.Map(location=[35.68, 139.76], zoom_start=10, tiles='Stamen Toner') # 地図の表示 m
上記のコードでは、東京を中心とした地図を作成し、背景地図にStamen Tonerを使用しています。
レイヤーの追加
次に、folium.GeoJson()関数を使って、GeoJSONデータをレイヤーとして追加します。style_function引数でレイヤーのスタイルを、tooltip引数でマウスオーバー時のツールチップを設定できます。
import folium
import geopandas as gpd
# 地図の作成
m = folium.Map(location=[35.68, 139.76], zoom_start=10)
# GeoJSONデータの読み込み
data = gpd.read_file('data.geojson')
# レイヤーの追加
folium.GeoJson(data,
name='Layer',
style_function=lambda feature: {'fillColor': 'blue', 'color': 'black'},
tooltip=folium.GeoJsonTooltip(fields=['name', 'population'])
).add_to(m)
# 地図の表示
m
上記のコードでは、data.geojsonというGeoJSONファイルを読み込み、レイヤーとして追加しています。style_functionで塗りつぶしの色と境界線の色を指定し、tooltipでnameとpopulationの値をツールチップに表示するように設定しています。
マーカーの追加
folium.Marker()関数を使って、地図上にマーカーを追加できます。location引数でマーカーの座標、popup引数でクリック時のポップアップ内容、icon引数でマーカーのアイコンを指定します。
import folium # 地図の作成 m = folium.Map(location=[35.68, 139.76], zoom_start=10) # マーカーの追加 folium.Marker(location=[35.68, 139.76], popup='Tokyo', icon=folium.Icon(icon='home')).add_to(m) # 地図の表示 m
上記のコードでは、東京の座標にマーカーを追加し、クリック時に「Tokyo」というポップアップを表示するように設定しています。また、マーカーのアイコンを家のアイコンに変更しています。
以上が、foliumの基本的な使い方です。geopandasと組み合わせることで、以下のような地理空間データの可視化が可能になります。
- ポイントデータをマーカーとして表示
- ラインデータをポリラインとして表示
- ポリゴンデータをポリゴンとして表示
- 属性データをツールチップやポップアップで表示
foliumを使えば、インタラクティブな地図を簡単に作成でき、データの探索や理解を深めることができます。ぜひ、geopandasと組み合わせて、自分のデータを地図上に可視化してみてください。
次章では、実際のデータ分析の現場で役立つ、geopandasの実践的な活用例を紹介します。
業務で使える!geopandasの実践的な活用例10選
geopandasは、実際のデータ分析の現場でも広く活用されています。本章では、geopandasを業務で活用する上で参考になる、実践的な活用例を10個紹介します。各活用例の目的、手順、工夫点などを解説するとともに、コード例も交えて具体的な実装イメージを持てるようにします。
クロロプレス地図の作成
クロロプレス地図は、地域ごとの統計データを視覚的に比較するのに便利です。geopandasを使えば、以下の手順でクロロプレス地図を作成できます。
- 統計データをポリゴンデータと空間結合する
- ポリゴンを統計値に応じて色分けする
- 凡例やラベルを追加して地図をカスタマイズする
import geopandas as gpd
import matplotlib.pyplot as plt
# ポリゴンデータと統計データの読み込み
polygons = gpd.read_file('polygons.shp')
stats = pd.read_csv('stats.csv')
# 空間結合
merged = polygons.merge(stats, on='id')
# 色分けして可視化
merged.plot(column='value', cmap='OrRd', edgecolor='black', linewidth=0.5, figsize=(10, 10))
plt.title('Choropleth Map')
plt.colorbar(label='Value')
plt.show()
ポイントは、カラーマップの選択、凡例の表示、ラベルの配置など、地図の見やすさを意識することです。
人口分布の可視化
人口分布を把握することは、マーケティングや都市計画などの分野で重要です。geopandasを使えば、以下の手順で人口分布を可視化できます。
- 人口データをポイントデータに変換する
- カーネル密度推定を行い、密度の高い地域を可視化する
- 透明度や色の設定で、見やすい地図にカスタマイズする
import geopandas as gpd
import numpy as np
import folium
# 人口データの読み込み
population = gpd.read_file('population.shp')
# カーネル密度推定
population['density'] = population['population'] / population.area
density = population.set_geometry(population.centroid).dissolve(by='density', aggfunc='sum')
# 可視化
m = folium.Map(location=[35.68, 139.76], zoom_start=10)
folium.Choropleth(
geo_data=density.geometry,
name='Population Density',
data=density,
columns=['density', 'density'],
key_on='feature.properties.density',
fill_color='YlOrRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='Population Density'
).add_to(m)
m
ポイントは、バンド幅の設定、カラーマップの選択、透明度の調整など、密度の分布が明確に伝わるようにすることです。
商圏分析への活用
商圏分析は、小売業などで店舗の最適立地を決める上で重要な分析です。geopandasを使えば、以下の手順で商圏分析を行えます。
- 店舗データと人口データを読み込む
- 店舗を中心としたバッファを作成する
- バッファ内の人口を集計し、商圏の特徴を把握する
import geopandas as gpd
# 店舗データと人口データの読み込み
stores = gpd.read_file('stores.shp')
population = gpd.read_file('population.shp')
# バッファの作成
stores_buffer = stores.buffer(1000)
# 空間結合
population_in_buffer = gpd.sjoin(population, gpd.GeoDataFrame(geometry=stores_buffer))
# 店舗ごとの商圏人口を集計
trade_area_population = population_in_buffer.groupby('index_right').sum()['population']
print(trade_area_population)
ポイントは、バッファの距離設定、人口データの集計方法など、商圏の定義や評価指標を適切に設定することです。
地価分析への活用
地価は、不動産開発や投資の意思決定に大きな影響を与えます。geopandasを使えば、以下の手順で地価の分布と要因を分析できます。
- 地価データと各種の地理空間データを読み込む
- 地価データと地理空間データを空間結合する
- 重回帰分析などで、地価の要因を特定する
import geopandas as gpd
import statsmodels.formula.api as smf
# 地価データと地理空間データの読み込み
land_prices = gpd.read_file('land_prices.shp')
stations = gpd.read_file('stations.shp')
parks = gpd.read_file('parks.shp')
# 最寄り駅までの距離を計算
land_prices['dist_to_station'] = land_prices.geometry.apply(lambda x: stations.distance(x).min())
# 最寄り公園までの距離を計算
land_prices['dist_to_park'] = land_prices.geometry.apply(lambda x: parks.distance(x).min())
# 重回帰分析
model = smf.ols('price ~ dist_to_station + dist_to_park', data=land_prices).fit()
print(model.summary())
ポイントは、説明変数の選択、空間的自己相関の考慮、モデルの評価など、地価の要因を適切に特定することです。
防災分析への活用
自然災害のリスクを把握し、適切な防災対策を講じることは、社会の安全・安心につながります。geopandasを使えば、以下の手順で防災分析を行えます。
- ハザードマップと建物データを読み込む
- ハザードマップと建物データを重ね合わせる
- 建物ごとのリスクを評価し、可視化する
import geopandas as gpd
# ハザードマップと建物データの読み込み
hazard_map = gpd.read_file('hazard_map.shp')
buildings = gpd.read_file('buildings.shp')
# 空間結合
buildings_at_risk = gpd.sjoin(buildings, hazard_map, op='within')
# リスクの高い建物を可視化
buildings_at_risk.plot(column='risk', cmap='YlOrRd', edgecolor='black', linewidth=0.5, figsize=(10, 10))
ポイントは、適切なハザードデータの選択、リスク評価の手法、結果の解釈など、防災上の意義を踏まえた分析を行うことです。
以上、geopandasの実践的な活用例を10個紹介しました。他にも、不動産評価、環境アセスメント、交通量分析、犯罪分析、選挙分析など、様々な分野でgeopandasが活躍しています。
実務でgeopandasを活用する際は、分析の目的や手順を明確にした上で、適切なデータや手法を選択することが大切です。また、geopandasと他のPythonライブラリを組み合わせることで、より高度で複雑な分析も可能になります。
ぜひ、これらの活用例を参考に、自身の業務でもgeopandasを活用してみてください。地理空間データ分析のスキルは、データサイエンティストにとって大きな武器になるはずです。
次章では、geopandasのメリットとデメリット、他のGISツールとの違いを整理します。
geopandasのメリット・デメリット。ArcGISなど他ツールとの違いは?
geopandasは、Pythonユーザーにとって強力な地理空間データ分析ツールですが、他のGISツールと比べると、メリットとデメリットがあります。本章では、geopandasの特徴を整理し、代表的なGISソフトウェアであるArcGISやQGISとの違いを解説します。
geopandasのメリット
geopandasの最大のメリットは、Pythonの豊富な機械学習やデータ分析ライブラリと組み合わせて使える点です。例えば、以下のようにscikit-learnと組み合わせて、地理空間データのクラスタリングを行うことができます。
import geopandas as gpd
from sklearn.cluster import KMeans
# データの読み込み
data = gpd.read_file('data.shp')
# 座標データの抽出
coords = data.geometry.apply(lambda x: [x.x, x.y])
# クラスタリング
kmeans = KMeans(n_clusters=5).fit(coords)
data['cluster'] = kmeans.labels_
# 結果の可視化
data.plot(column='cluster', categorical=True, legend=True)
また、pandasのデータ処理機能を活用できるのも大きな利点です。GeoPandasのデータ構造により、地理空間データの処理が効率的に行えます。
さらに、geopandasはオープンソースで無償利用が可能であり、Jupyter Notebookと親和性が高いため、インタラクティブな分析が可能です。
geopandasのデメリット
一方で、geopandasにはいくつかのデメリットもあります。まず、大規模なデータセットの処理には向いていません。また、高度な地図作成機能や空間分析機能は限定的です。
例えば、以下のようにfoliumと連携して、インタラクティブな地図を作成することはできますが、ArcGISやQGISほど細かなカスタマイズはできません。
import geopandas as gpd
import folium
# データの読み込み
data = gpd.read_file('data.shp')
# 地図の作成
m = folium.Map(location=[data.geometry.centroid.y, data.geometry.centroid.x], zoom_start=10)
# レイヤーの追加
folium.GeoJson(data).add_to(m)
# 地図の表示
m
また、ラスターデータの処理には別のライブラリ(rasterioなど)が必要であり、商用GISソフトと比べると、分析手法や可視化の選択肢が少ないのも事実です。
ArcGISとの違い
ArcGISは、ESRI社の商用GISソフトウェアです。以下のような特徴があります。
- 高度な地図作成機能や空間分析機能を備えている
- GUIベースの操作が中心で、プログラミングの知識は必須ではない
- 大規模なデータセットの処理に適している
- 高価なライセンス料が必要
一方、geopandasは以下のような特徴があります。
- Pythonのプログラミングスキルが必要
- 無償で利用できる
- 大規模データの処理には向いていない
- 高度な地図作成や空間分析には制限がある
QGISとの違い
QGISは、オープンソースのGISソフトウェアです。以下のような特徴があります。
- GUIベースの操作が中心だが、Pythonプラグインによる拡張が可能
- 高度な地図作成機能や空間分析機能を備えている
- 無償で利用できる
- ユーザーコミュニティが活発で、サポートが充実している
一方、geopandasは以下のような特徴があります。
- Pythonのプログラミングスキルが必要
- インタラクティブな分析が得意
- 機械学習などの他のPythonライブラリとの連携が容易
- 地理空間データ処理の知識が必要
以上のように、geopandasには他のGISツールにはない強みがある一方で、制限事項もあります。分析の目的や対象データの特性を踏まえて、適切なツールを選択することが重要です。
geopandasは、Pythonを使ったデータ分析と地理空間データ処理を融合させたい場合に、特に力を発揮するツールだと言えるでしょう。ただし、地理空間データ処理の知識は必須です。Shapefile、GeoJSON、投影法などの基本概念を理解した上で、geopandasを活用することをおすすめします。
次章では、geopandasのさらに発展的な使い方として、上級者向けのTipsを紹介します。
geopandasのさらに詳しい使い方。上級者向けTips集
geopandasの基本的な使い方をマスターしたら、さらに発展的な使い方にチャレンジしてみましょう。本章では、シェープファイル以外のデータの読み込み方、スタイルの設定方法、プロット図の保存方法など、上級者向けのTipsを紹介します。
シェープファイル以外のデータの読み込み方
geopandasは、シェープファイル以外にも様々な地理空間データ形式をサポートしています。以下は、代表的なデータ形式の読み込み方法です。
- GeoJSONの読み込み:
gpd.read_file('data.geojson') - TopoJSONの読み込み:
gpd.read_file('data.topojson') - PostGISからの読み込み:
gpd.read_postgis(sql, con) - SparkGeoからの読み込み:
gpd.read_file('data.parquet')
これらのデータ形式を読み込む際は、適切なデータパスとオプションを指定する必要があります。
スタイルの設定方法
geopandasのプロット図は、plot()メソッドの引数を使ってカスタマイズできます。色、線の太さ、透明度などを自由に設定できるため、見やすく美しい地図を作成できます。
import geopandas as gpd
import matplotlib.pyplot as plt
data = gpd.read_file('data.shp')
data.plot(column='value', cmap='viridis', linewidth=0.5, edgecolor='black', figsize=(10, 10))
plt.title('Custom Style Plot')
plt.show()
また、GeoSeries.plot()を使えば、個別のジオメトリに対して、異なるスタイルを適用することもできます。matplotlibのスタイル設定も活用できるので、自由度の高い可視化が可能です。
プロット図の保存方法
geopandasで作成したプロット図は、plt.savefig()を使って、画像ファイルとして保存できます。PNG、JPEG、SVG、PDFなど、様々な画像フォーマットに対応しています。
import geopandas as gpd
import matplotlib.pyplot as plt
data = gpd.read_file('data.shp')
data.plot(figsize=(10, 10))
plt.savefig('plot.png', dpi=300, bbox_inches='tight')
dpi引数で解像度を、bbox_inches引数で余白の調整を行えます。高品質の地図画像を保存して、レポートやプレゼンテーションに活用しましょう。
よく使う空間演算関数の紹介
geopandasには、ジオメトリ同士の空間演算を行うための便利な関数が用意されています。以下は、よく使う空間演算関数の一覧です。
buffer(): ジオメトリの周りにバッファを作成intersection(): 2つのジオメトリの交差部分を返すunion(): 2つ以上のジオメトリの和集合を返すdifference(): 2つのジオメトリの差集合を返すsymmetric_difference(): 2つのジオメトリの対称差を返す
これらの関数を使って、複雑な空間分析を行うことができます。
import geopandas as gpd
data1 = gpd.read_file('data1.shp')
data2 = gpd.read_file('data2.shp')
buffer_data = data1.buffer(100)
intersection_data = data1.intersection(data2)
union_data = data1.union(data2)
difference_data = data1.difference(data2)
symdiff_data = data1.symmetric_difference(data2)
空間演算の結果は、新しいGeoDataFrameとして返されます。元のデータと組み合わせて分析を進めましょう。
その他にも、geopandasを発展的に活用する方法があります。
- 地理空間データの処理をDask(並列処理ライブラリ)で高速化
- kepler.glと連携して、WebGLベースのインタラクティブな地図を作成
- rasterioと組み合わせて、ラスターデータの処理を行う
- osmnxと連携して、OpenStreetMapからデータを取得・分析する
- geoplotと組み合わせて、高度な地図の可視化を行う
これらのテクニックを使いこなせば、geopandasでより高度で実践的な地理空間データ分析が可能になります。
ただし、初心者ユーザーにとっては、これらの発展的な使い方はハードルが高いかもしれません。基本的な使い方をしっかりとマスターした上で、徐々にステップアップしていくことをおすすめします。
geopandasは、Pythonユーザーにとって非常に強力な地理空間データ分析ツールです。本記事で紹介した基本的な使い方から応用的な使い方まで、幅広いテクニックを身につけて、データサイエンティストとしてのスキルを磨いていきましょう。
Happy GeoAnalysis!

